AWS Bedrockとは?使い方・料金・対応モデル・他AIツールとの違いを徹底解説
企業の生成AI導入を加速させる「AWS Bedrock」は、Amazonが提供するフルマネージド型の生成AI基盤サービスです。
コード不要で大規模言語モデル(LLM)や画像生成AIを簡単に使え、既存のAWS環境との連携もスムーズです。
ClaudeやLlama、Titanなど複数のモデルを目的別に使い分けられる柔軟性が特徴です。
本記事では、AWS Bedrockの基本から料金体系、使い方、他AIツールとの違いまでを網羅的に解説します。導入検討中の企業担当者は必見です。
また、弊社ではマッキンゼーやGAFA出身のAIエキスパートがAI導入に関する無料相談を承っております。
無料相談は先着20社様限定で「貴社のAI活用余地分析レポート」を無償でご提供するキャンペーンも実施中です。
ご興味をお持ちの方は、以下のリンクよりご連絡ください:
AI導入に関する無料相談はこちら
資料請求はこちら

AI導入.comを提供するビルドAI株式会社 代表取締役。トロント大学コンピューターサイエンス学科卒業。株式会社ANIFTYを創業後、世界初のブロックチェーンサービスを開発し、東証プライム上場企業に売却。その後、マッキンゼー・アンド・カンパニーにコンサルタントとして入社。マッキンゼー日本オフィス初の生成AIプロジェクトに従事後、ビルドAI株式会社を創業。

AWS Bedrockとは?

生成AIをビジネスに導入する企業が増えるなかで、Amazonが提供する「AWS Bedrock」は、複数の高性能AIモデルを簡単に活用できる注目の基盤サービスです。
本章では、AWS Bedrockの基本構造と活用イメージを、テキスト・画像生成の観点から具体的に解説します。
AWS Bedrockの仕組み
AWS Bedrockの仕組みは、複数の大規模言語モデル(LLM)をAPI経由で利用できる構成です。
Amazon Titanをはじめ、AnthropicのClaudeやMetaのLlamaなど主要なAIモデルが統合されており、アプリ開発者は独自の基盤構築なしに直接生成AI機能を実装できます。
Amazon Bedrockの活用例
Amazon Bedrockの活用例には、業務の自動化やカスタマー対応の高度化があります。
例えば、FAQの自動応答、マーケティング用コンテンツ生成、ECサイトでのレコメンド最適化など、テキスト・画像両面での利用が広がっています。
テキスト生成
テキスト生成は、チャットボットやレポート自動作成に活用できます。
Amazon Bedrockでは、選択したモデルがプロンプトに応じた自然な文章を生成し、メール草案や製品説明文の作成が自動化されます。
画像生成
画像生成は、広告バナーやSNS投稿用ビジュアルの作成に活用できます。
プロンプトから任意のイメージを生成できるため、デザインリソースを持たない企業でも、高品質なビジュアルコンテンツを短時間で制作できます。
Amazon Bedrockを利用するメリット

生成AIの導入においては、使いやすさと柔軟性、そして既存システムとの連携性が大きなポイントになります。
Amazon Bedrockはこれらを高い水準で実現しており、企業のDX推進を後押しする存在です。
本章では、Bedrockが持つ3つの主要な利点を具体的に解説します。
複数モデルを柔軟に使い分け可能
企業の利用目的に応じて、AnthropicのClaude、MetaのLlama、Amazon Titanなど複数モデルを柔軟に使い分け可能なことが大きな利点です。
生成タスクの精度や応答速度、コスト構造の違いを踏まえて適切なモデルを選択できるため、目的に合った最適なAI活用が実現できます。
開発フェーズや業務内容に応じた切り替えも容易で、導入から運用までの負担軽減にもつながります。
基盤モデルを自社向けにカスタマイズ可能
独自の業務データやFAQを学習させることで、カスタマーサポートや社内ナレッジ検索の精度が高まり、自社特有の言い回しや業務フローに沿った回答が可能になります。
このように、基盤モデルを自社向けにカスタマイズ可能な点がAmazon Bedrockを利用するメリットです。
AWS各種サービスとシームレスに連携可能
Amazon Bedrockは、S3・Lambda・SageMaker・CloudWatchなどのAWS各種サービスとシームレスに連携可能です。
これにより、ストレージ管理、アプリ実行、学習パイプラインの構築、ログモニタリングといった業務プロセスを一貫して自動化できます。
たとえば、S3からデータを読み込み、生成AIで処理し、結果をLambdaで別システムへ転送するといったワークフローもノーコードで実現可能です。
既存のAWSインフラを活かしたスムーズな導入と、運用効率の最大化が図れる点が、企業にとっての大きなメリットです。
AWS Bedrockで利用できるモデル

AWS Bedrockでは、複数の有力な生成AIモデルを目的に応じて柔軟に選択できます。 ベンダーごとの特性や強みを理解することで、活用シーンに最適なモデル選定が可能になります。
本章では、Bedrockで利用可能な6つの代表的なモデルについて、それぞれの特徴と活用シーンを詳しく解説します。
Amazon Titan
Amazon Titanは、AWSが独自開発した高精度な大規模言語モデルです。
機密性の高い処理や社内特化型アプリケーションに適しており、セキュリティや一貫性が求められる企業活用に向いています。 文書要約・分類・検索補助などのタスクにも対応しています。
A121 Labs(Jurassic)
A121 Labs(Jurassic)は、長文生成や柔軟な表現力に優れたモデルです。
豊富な語彙力と自然な文章構成が特徴で、ストーリー生成やマーケティング用途に適しています。 多様な言語表現を扱える点で、クリエイティブ領域に強みを発揮します。
Anthropic(Claude)
Anthropic(Claude)は、安全性と倫理性に配慮された高品質なAIモデルです。
チャットボットや顧客対応など、人との対話を重視する用途におすすめです。 高度なガードレールが組み込まれており、センシティブな対話にも対応可能です。
Cohere(Command, Embed)
Cohere(Command, Embed)は、検索・分類・意味理解に強いモデルです。
テキストの意味を深く理解し、自然言語ベースの検索エンジンや分類システムの構築に向いています。 コマンド系列は生成用途、Embed系列は検索・分析用途に活用されます。
Meta(Llama)
Meta(Llama)は、研究開発および軽量運用を重視する企業に適したオープンモデルです。
学術利用や自社カスタマイズに強みがあり、クラウド外での実装にも柔軟に対応できます。 コストを抑えつつ高精度な出力が求められる場面で効果を発揮します。
Mistral AI(Mistral)
Mistral AI(Mistral)は、推論速度と軽量性に優れた次世代LLMです。
高速処理と高いコストパフォーマンスが特徴で、リアルタイム処理やエッジ環境でのAI活用に向いています。 省メモリ・高効率でありながら、自然な応答生成も可能です。
AWS Bedrockの使い方

AWS Bedrockを活用するためには、初期アクセスからモデルの選択、生成タスクの実行まで一連の操作を把握する必要があります。
GUI上の設定項目や各種選択肢の違いも理解しておくことで、業務に即した運用がスムーズになります。
本章では、実際の利用手順をステップごとにわかりやすく丁寧に解説します。
アクセス
AWS Bedrockのコンソール画面にアクセスするには、AWSマネジメントコンソール上部の検索バーに「Bedrock」と入力し、表示されたサービスを選択します。
Bedrockのサービスページが開いたら、「Get started with Amazon Bedrock」ボタンをクリックすることで利用を開始できます。
初期設定
利用を開始するには、最初にリージョンを選び、IAMユーザーにAmazon Bedrockの利用に必要な権限を設定する必要があります。
Bedrockは現在、対応リージョンが限られているため、サービス提供エリアに切り替える必要があります。また、IAMユーザーには「AmazonBedrockFullAccess」などのポリシーを付与しておくと、スムーズに操作を開始できます。
使用モデルの選択
ダッシュボードから「モデル選択」に進み、Titan・Claude・Llamaなどの基盤モデルを選びます。 用途に応じたパフォーマンスやコスト指標も参考にしてください。
「Chat」の実行
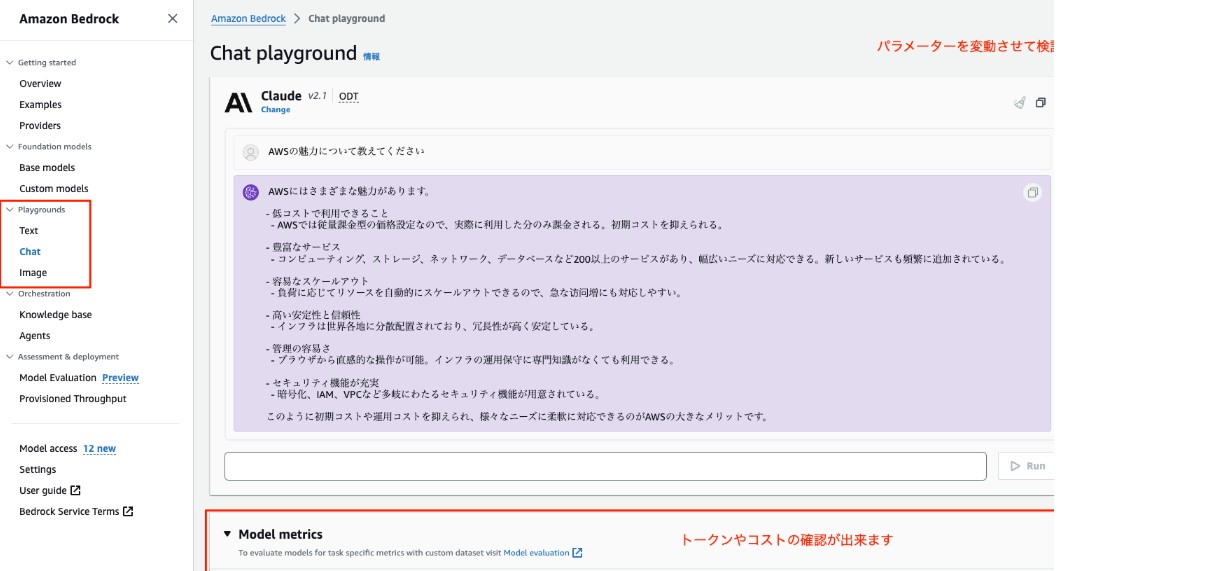
AWS Bedrockの「Chat」機能を使用するには、以下の手順を実行します。
左側のナビゲーションメニューから「Playgrounds」を選択し、「Chat」をクリックします。
「Select model」ボタンをクリックし、使用するモデル(例:AnthropicのClaude 3.5 Sonnet)を選択して「Apply」をクリックします。
画面下部のテキスト入力欄に質問や指示を入力し、「Run」ボタンをクリックすると、モデルからの応答が表示されます。

「Text」の実行
AWS Bedrockの「Text」機能を使用するには、以下の手順を実行します。
左側のナビゲーションメニューから「Playgrounds」を選択し、「Text」をクリックします。 「Select model」ボタンをクリックし、使用するモデル(例:AmazonのTitan Text G1 - Express v1)を選択して「Apply」をクリックします。
画面下部のテキスト入力欄に生成したい内容の指示を入力し、「Run」ボタンをクリックすると、モデルからの生成されたテキストが表示されます。
事前に用意したプロンプトや社内ドキュメントを使ってテストすることが推奨されます。
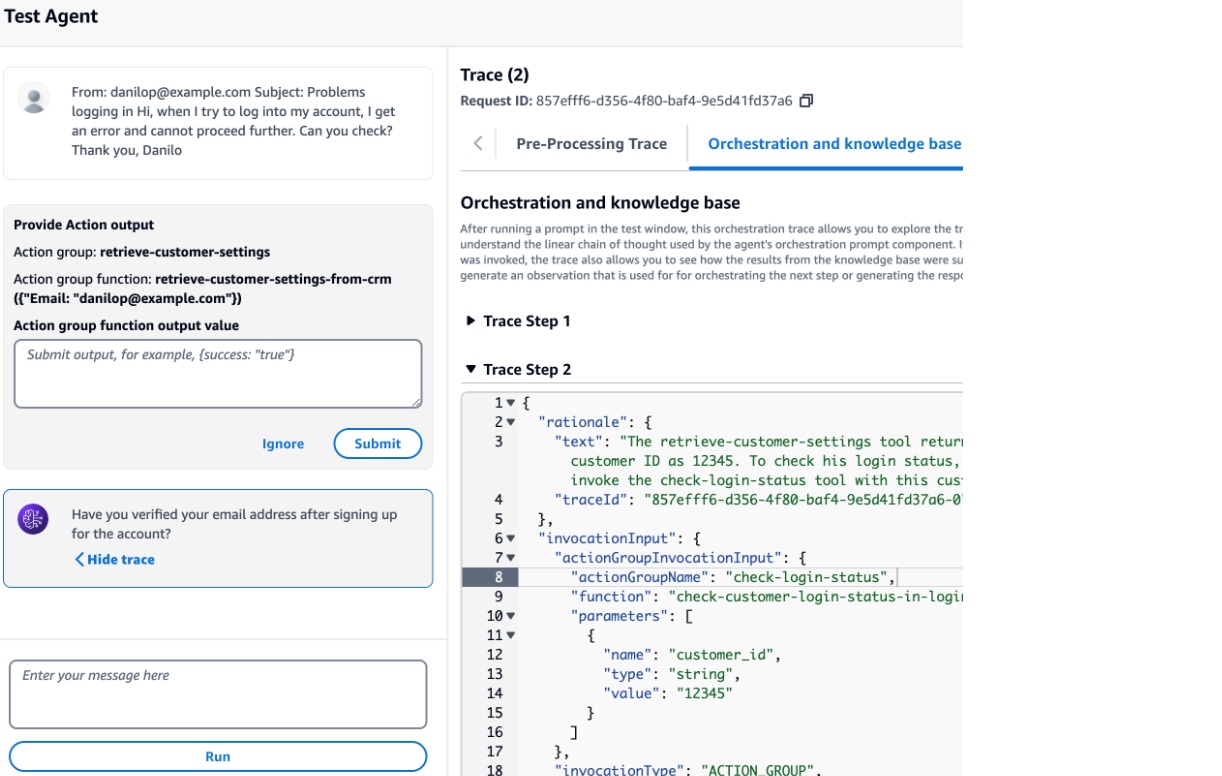
「Image」の実行
「Image」の実行では、テキストで指示した内容に応じて、AIがリアルな画像やイラストを自動生成することが可能です。
プロンプト(入力文)には「青空の下に立つビジネスマン」や「未来的な都市の風景」といった具体的なイメージを入力します。
生成された画像はその場でプレビューされ、ダウンロードして社内資料やプレゼン資料、SNS投稿などに活用することもできます。
画像生成の精度は使用するモデルによって異なるため、目的に応じて最適なモデルを選ぶことがポイントです。
画像生成機能は、視覚的な訴求が重要な業務において強力な武器になります。適切なモデルを選び、プロンプトを工夫することで、業務効率とクリエイティブの質を同時に高めることが可能です。
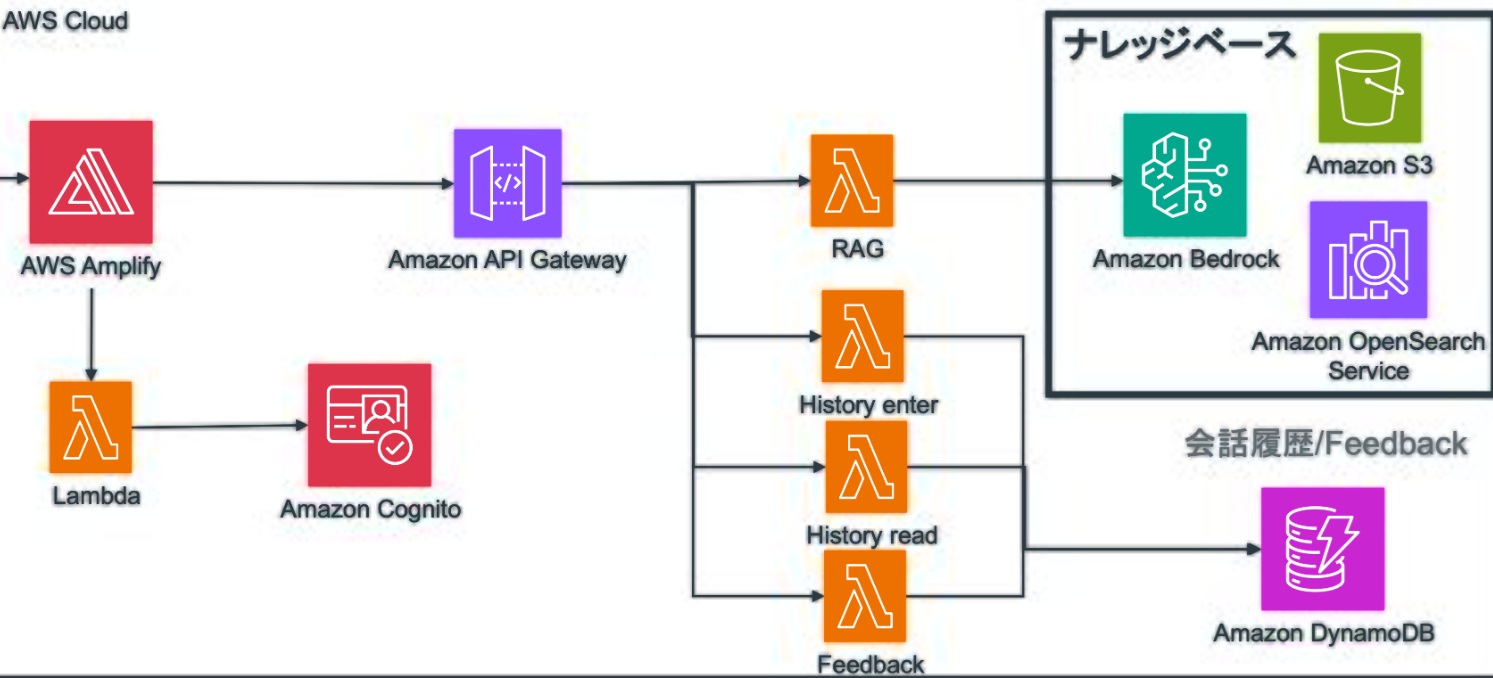
AWS Bedrock のAPI使用方法
AWS Bedrockを自社サービスや業務システムに組み込むためには、APIの活用が不可欠です。
本章では、基本的なAPIの使い方から、近年注目されているRAG(Retrieval-Augmented Generation)との連携方法まで、実務で役立つポイントを解説します。
APIの呼び出し方法
APIの呼び出し方法は、指定した基盤モデルに対してエンドポイント経由でリクエストを送ることです。
リクエストにはモデルIDやプロンプト内容、出力オプションを含め、レスポンスとして生成結果が返ってきます。 Amazon SDKやHTTPクライアントを通じて実装でき、セキュリティ認証にはIAMのアクセスキーが必要です。
RAGとの連携方法
RAGとの連携方法は、事前に用意した社内文書やナレッジデータベースを検索し、その情報をプロンプトに組み込む仕組みです。
検索処理にはAmazon KendraやOpenSearchを用い、生成モデルに情報を補完させることで精度と信頼性を高められます。
RAGは、FAQ生成や専門領域の回答精度向上に特に効果的です。
AWS Bedrockの料金体系

AIサービスの導入にあたって、コスト構造の把握は欠かせません。 AWS Bedrockは利用形態に応じて柔軟な料金体系を提供しており、用途や予算に合わせた選択が可能です。
本章では、4つの主要な課金モデルについて、それぞれの特徴と適した利用シーンを解説します。
オンデマンド
オンデマンドは、使用したリクエスト数や生成トークン数に応じて課金される柔軟な料金モデルです。
初期費用不要で、利用した分だけ支払うため、小規模な検証やPoC(概念実証)に適しています。 短期集中型の開発にもフィットし、コスト管理のしやすさが特徴です。
バッチモード
バッチモードは、大量のテキストや画像などを一括処理する際に適した課金モデルです。
スケジューリングによる処理実行が可能で、処理効率とコスト効率のバランスを取りやすいのがメリットです。
定期レポート作成や大量データ処理の自動化用途に活用されています。
プロビジョニング
プロビジョニングは、あらかじめ処理リソースを確保しておくことで、安定したパフォーマンスと予測可能なコストを実現するモデルです。
常時稼働するシステムや、大規模運用を前提としたAI導入に向いています。
リソース不足による遅延を防ぎたい場合に適しています。
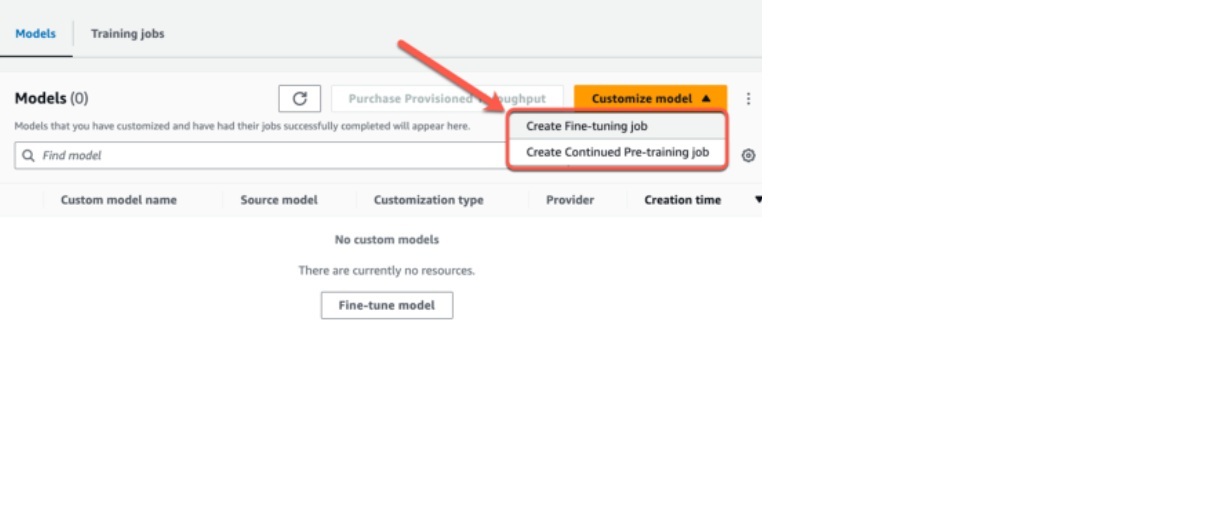
カスタマイズ
カスタマイズは、独自の要件に基づいてモデルを再学習・調整するプロセスにかかる費用が対象です。
料金は作業内容やデータ規模によって変動し、初期導入時や長期運用前提のモデル最適化に活用されます。
高精度が求められる業務用途においては、費用対効果の高い選択となり得ます。
他のAIツールとの比較
AIツールの選定においては、自社の業務目的や導入環境に応じた適切な比較が不可欠です。
本章では、AWS Bedrockと代表的な他ツールであるAWS KendraおよびChatGPTを比較し、用途別にどちらが適しているかを明確に整理します。
AWS KendraとBedrockの違い
AWS Kendraは検索特化型、Bedrockは生成AI基盤として機能が異なります。業務目的に応じた使い分けが重要です。
| 比較軸 | AWS Kendra | AWS Bedrock |
|---|---|---|
| 主な用途 | ナレッジ検索・社内FAQの検索精度向上 | テキスト生成、画像生成など生成AIの多目的活用 |
| モデルの性質 | 検索用アルゴリズムに特化 | 複数の大規模言語モデル(Claude、Llama等)に対応 |
| カスタマイズ性 | 検索対象のチューニング中心 | モデル自体のカスタマイズが可能(自社データで学習) |
| 連携性 | AWS内の既存データソースと容易に連携 | AWSサービス全般とシームレスに連携可能 |
| 適している業務例 | ナレッジベース検索、カスタマーサポート | コンテンツ生成、対話AI、マーケティング支援、業務効率化など |
選定の補足:明確なナレッジ検索の精度を求める場合はKendra、生成や応答処理など幅広いAIタスクがある場合はBedrockの導入が適しています。
ChatGPTとBedrockの違い
ChatGPTは単体利用向き、Bedrockは複数モデルを統合的に活用できる企業向け基盤です。用途に応じた選定が求められます。
| 比較軸 | ChatGPT(OpenAI) | AWS Bedrock |
|---|---|---|
| 主な用途 | 会話AI、要約、翻訳、テキスト生成 | テキスト・画像生成、業務向け生成AIの組み込み |
| モデル選択 | GPTシリーズのみ | 複数モデル(Titan、Claude、Llama、Mistral等)から選択可能 |
| カスタマイズ性 | プロンプト設計による調整が中心 | 独自データによるファインチューニング対応 |
| 導入のしやすさ | Webツールとして簡単に利用可能 | AWS環境内での運用が前提、スケーラビリティに優れる |
| 適している業務例 | 汎用的なチャット対応、文書作成 | エンタープライズ向けの業務プロセス統合、専用ワークフローの構築が必要な場面 |
選定の補足:個人や中小規模での導入・利用はChatGPTが適しており、大規模業務連携やセキュリティを重視する企業用途にはBedrockが推奨されます。
AWS Bedrockに関するよくある質問

AWS Bedrockの導入を検討する際、多くの企業が共通して抱く疑問があります。
本章では、セキュリティ対策や学習リソースに関する代表的な2つの質問に対して、端的かつ実務に役立つ形で回答します。 導入判断や社内説明資料づくりにもご活用ください。
AWS bedrock の ガードレールとは?
AWS Bedrockのガードレールとは、不適切な出力や誤情報の生成を抑えるための制御機能です。
コンテンツの安全性・倫理性を担保するため、プロンプト制限・レスポンスフィルター・出力スコアリングなど複数の機能が提供されています。 社外向け応答やコンプライアンスが求められる業務にも安心して導入できます。
AWS Bedrockのblackbeltでできることは?
AWS BedrockのBlack Beltでは、操作方法から活用ノウハウまで実務に役立つ情報を体系的に学べます。
Amazon公式が提供する技術セミナーであり、Bedrockの仕組みやモデル活用、API連携、セキュリティ設定などを動画や資料で詳しく解説しています。
エンジニアだけでなく、企画・導入を検討するビジネス部門の担当者にも有益な内容が揃っており、社内研修や意思決定の材料としても活用できます。
まとめ
本記事では、AWS Bedrockの基本から活用例、料金、対応モデル、他ツールとの違いまでを解説しました。
複数の基盤モデルを使い分けられる柔軟性や、AWSサービスとの高い親和性は、企業の生成AI導入において大きな強みです。
生成AIは一部の先進企業だけでなく、今や幅広い企業にとって現実的な選択肢となっています。
まずは小規模なPoCから始め、現場でその実力を確認することが、競争力向上への第一歩です。