ローカルLLMとは?おすすめモデル12選・ビジネス導入事例・使い方を解説
近年、多くの大規模言語モデル(LLM)が登場していますが、その中でもローカルLLMが注目を集めています。
ローカルLLMは、データ保護やセキュリティの観点から大きなメリットがある技術です。
本記事では、ローカルLLMの基礎知識から導入方法、日本語対応モデルの比較まで詳しく解説します。
セキュリティ重視のAI活用や自社環境での運用を検討している方は、ぜひ参考にしてください。
また、弊社ではマッキンゼーやGAFA出身のAIエキスパートがAI導入に関する無料相談を承っております。
無料相談は先着20社様限定で「貴社のAI活用余地分析レポート」を無償でご提供するキャンペーンも実施中です。
ご興味をお持ちの方は、以下のリンクよりご連絡ください:
AI導入に関する無料相談はこちら
資料請求はこちら

ローカルLLMとは

ローカルLLMとは、利用者自身の機器上で動作する大規模言語モデルです。ChatGPTなどのクラウドサービスとは異なり、データが外部に送信されないため、プライバシーとセキュリティを重視する場合に最適です。
特徴として、ネット接続なしで使えること、処理が全て自分の機器内で完結すること、そして個人のパソコンやMac、最新のスマートフォンでも動作可能なことが挙げられます。
最近では日本語に対応したローカルLLMモデルも増えており、実用的な選択肢が広がっています。
クラウド型LLMとの違い

ローカルLLMとクラウド型LLMの最大の違いは、処理場所とデータの管理方法にあります。
クラウド型LLMはOpenAIやGoogle、Anthropicなどの会社のサーバーで処理が行われるため、常にインターネット接続が必要です。一方、ローカルLLMは全ての処理が自分の機器内で完結するため、データが外部に漏れる心配がありません。
性能面では、クラウド型は大規模な計算資源を活用できるため高性能ですが、ローカルLLMは機器のスペックに依存し、比較的小さなモデルが主流です。
選択の際は、処理能力とプライバシーのバランスを考慮することが重要です。
ローカルLLMを導入するメリット

ローカルLLMを導入する最大のメリットは、データの自己管理によるプライバシー保護です。利用者のデータがクラウドに送信されないため、機密情報を扱う業務や個人情報保護が重要な場面に適しています。
また、インターネット接続に依存しないため、オフライン環境でも安定して利用できる点も大きな利点です。
利用者のデータがクラウドに送られないため、機密情報を扱う業務や個人の情報を守りたい場合に適しています。
また、ネット接続に依存しないため、オフライン環境でも安定して使える点も魅力です。
以下では、セキュリティ、コスト、カスタマイズ性という3つのメリットについて詳しく解説します。
セキュリティの向上

ローカルLLMの最大の利点はデータセキュリティの大幅な向上です。全ての処理がローカル環境内で完結するため、機密情報が外部に漏れるリスクがありません。
企業の内部文書や個人情報を扱う場合、ローカルLLMなら安全に処理できます。また、インターネット接続を必要としないため、ネットワーク経由の攻撃リスクも減少します。
クラウドサービスの利用が難しい規制の厳しい業界や、データ漏洩に敏感な組織にとって、ローカルLLMは理想的な選択肢となります。
コスト削減
クラウド型LLMサービスは利用量に応じた課金が一般的ですが、ローカルLLMは初期投資後の追加コストがほとんどかかりません。頻繁に利用する場合や大量のリクエストを処理する必要がある場合、長期的には大幅なコスト削減になります。
特にChatGPTのようなサブスクリプションモデルと比較すると、定期的な支払いが不要になる点は大きなメリットです。
高性能なGPUが必要なモデルもありますが、用途に応じた適切なモデル選択により、コストパフォーマンスの良いAI環境を構築できます。
カスタマイズ性の向上

ローカルLLMの大きな魅力は高いカスタマイズ性です。自分のニーズに合わせたモデル調整や、特定の分野に特化した学習が可能です。
オープンソースモデルをベースにした改良や、独自データでの追加学習により、特定の業界用語や専門知識に対応したAIを構築できます。
例えば法律分野や医療分野など、専門性の高い領域で活用する場合、その分野の文献で追加学習させることで精度を高められます。このような柔軟性は、クラウドサービスでは実現が難しい大きな利点です。
ローカルLLMが適用できる業務

ローカルLLMは様々なビジネスシーンで活用できます。ここでは業務別の具体的な活用例を紹介します。プライバシーとセキュリティを確保しながら、業務効率化を実現するローカルLLMの可能性を理解しましょう。
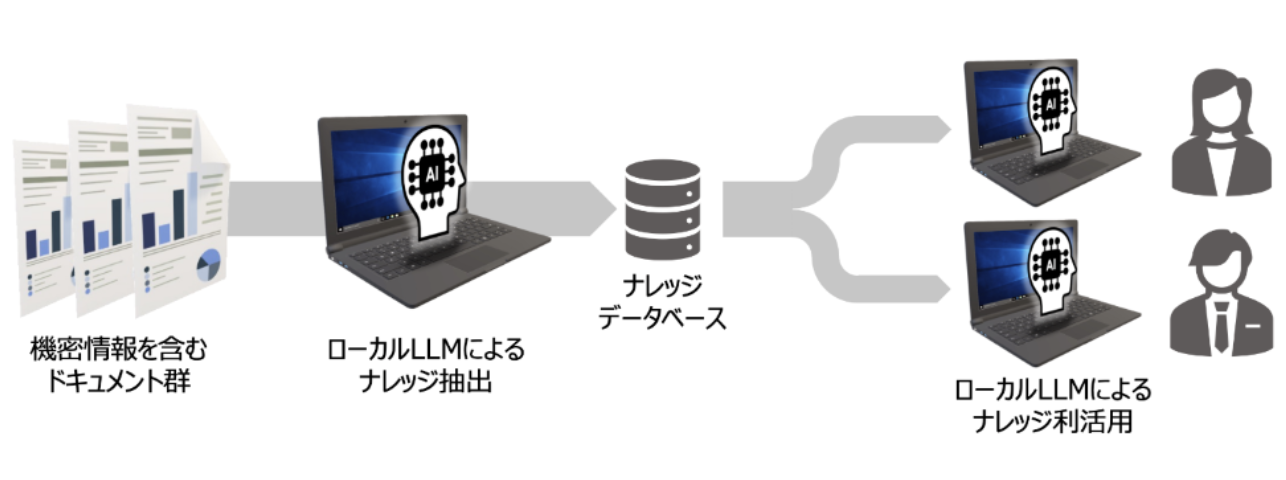
社内ドキュメント管理と知識検索

多くの企業では膨大な社内文書や技術資料が蓄積されていますが、必要な情報を素早く見つけることは容易ではありません。
ローカルLLMを用いたナレッジ管理システムでは、自然言語での質問に対して関連文書を検索し、適切な回答を提供できます。
特に機密性の高い社内文書や技術マニュアルなどを扱う場合、データを外部に送信せずに処理できるローカルLLMは理想的な選択肢です。RAG(検索拡張生成)技術と組み合わせることで、企業固有の専門用語や業界知識を考慮した正確な回答が得られます。
顧客サービスと問い合わせ対応

顧客情報は企業にとって最も機密性の高いデータの一つです。ローカルLLMを活用すれば、顧客データを外部に送信することなく、高度なサポート機能を提供できます。
例えば、過去の対応履歴や顧客情報をもとに、パーソナライズされた回答案の生成や、FAQ自動応答システムの構築が可能です。また、対応スクリプトの最適化や、複雑な問い合わせの分類・振り分けにも活用できます。
顧客情報の漏洩リスクを最小限に抑えながら、対応品質向上と業務効率化を同時に実現できる点が大きなメリットです。
ビジネス文書作成と編集支援

企業活動に必要な様々な文書作成にローカルLLMを活用できます。報告書、提案書、マニュアル、メールなど、競合分析や未発表の戦略情報など機密性の高い内容を含む場合、データの外部流出リスクを避けられます。
文書の草案作成や、対象読者に合わせた表現調整、複数バージョンの文書生成なども効率化できます。また、企業独自の文体やブランドガイドラインに合わせたカスタマイズも可能です。
社内向け資料や外部公開前の機密情報を含む文書作成もセキュアに行えるため、情報保護と生産性向上を両立させることができます。
法務・規制対応業務

契約書や法的文書の作成・分析は、高度な専門知識と正確性が求められる業務です。ローカルLLMを活用することで、契約書のレビュー支援や法的リスクの予備分析、条項の整合性チェックなどを効率化できます。
特に企業秘密を含む契約書や内部規定などは、外部サービスに送信せずに処理することが重要です。ローカルLLMを用いれば、文書の要約や比較、不明瞭な条項の明確化などをセキュアに行えます。
法令遵守のためのポリシー文書作成支援や、業界特有の規制に関する情報整理にも活用でき、コンプライアンス体制の強化につながります。
専門知識の文書化と技術資料作成

企業内には専門家の暗黙知や未公開の技術情報など、極めて機密性の高い情報が存在します。ローカルLLMを活用することで、これらの情報漏洩リスクなしに、専門知識の文書化や技術資料の作成を支援できます。
業務マニュアルの作成や、トラブルシューティングガイドの生成、専門的な報告書の要約なども効率化できます。また、社内の専門用語や独自の業務プロセスに特化した説明文書の生成も可能です。
特に知的財産保護が重要な分野では、データを完全に自社内で管理できるローカルLLMの価値が非常に高いといえます。
人事・人材開発業務

従業員情報は個人情報保護の観点から、特に慎重な取り扱いが求められます。ローカルLLMを活用することで、外部にデータを送信せずに、採用活動や人材育成を支援できます。
具体的には、求人票の作成、応募者の経歴書の分析、面接質問リストの生成などの採用支援が可能です。また、従業員評価フィードバックの文章化や、研修プログラムのパーソナライズなどの人材開発にも活用できます。
人事情報のプライバシー保護を確保しながら、採用プロセスの効率化や人材育成の質向上を実現できる点が大きなメリットです。
ローカルLLMの企業事例【業界別】
ローカルLLMは様々な業界で導入が進んでおり、セキュリティやプライバシーを重視する企業で特に活用されています。ここでは、完全にローカル環境で動作するLLMを導入した企業の実際の活用事例を紹介します。
金融業界での活用事例
金融業界は顧客の個人情報や取引データなど極めて機密性の高い情報を取り扱うため、セキュリティ対策としてローカルLLMの導入が進んでいます。
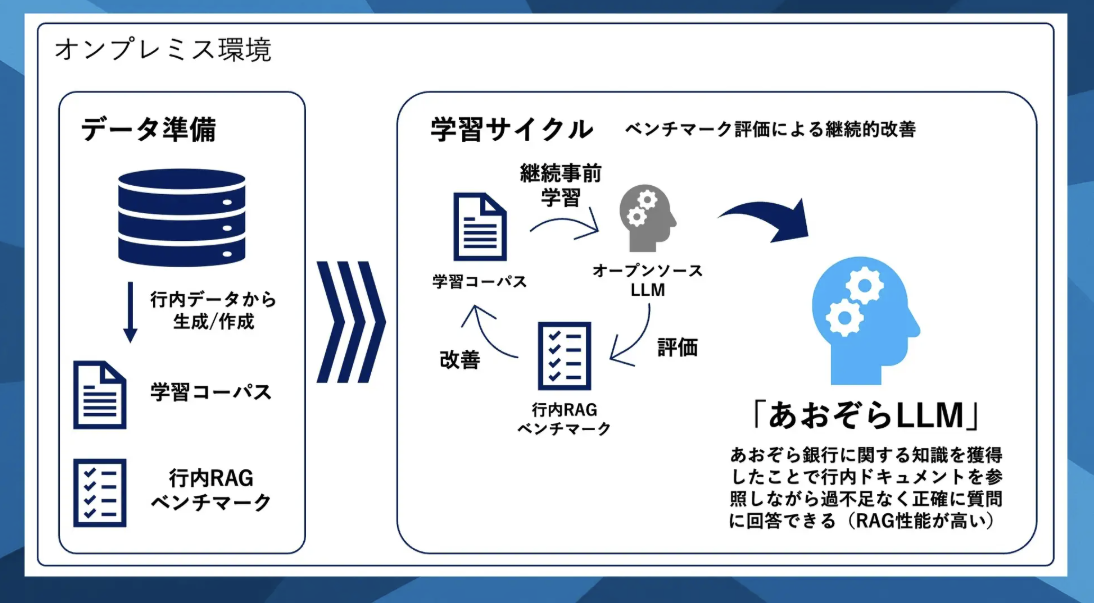
あおぞら銀行では、オンプレミス環境に自社特化型のローカルLLM「あおぞらLLM」を構築しました。金融業務や行内規定に関する知識をモデルに学習させることで、事務規定管理業務における応答精度が従来比130%に向上しています。
特に行内で使われる固有の用語について、その意味や関連性を正確に理解し、適切に回答できるようになりました。
用語認識の精度向上や業務体系の包括的理解が進み、当座貸越や証書貸付・手形貸付などの融資業務全体の構造を体系的に把握した回答ができるようになっています。
オンプレミス環境での導入により、クラウド型生成AIでは難しかったセキュリティの担保と社内情報の学習を両立させることに成功した事例として注目されています。
生命保険業での活用事例

生命保険業界でも、顧客情報の保護とAI活用の両立を目指す動きが加速しています。
ライフネット生命保険は、社員の生産性向上を目的に社内用生成AI(社内用LLM)を自社開発し導入しました。
導入から半年後の2025年1月時点で正社員の87%が利用する高い浸透率を達成し、導入開始から2ヶ月で利用者の業務時間を計152時間削減するなど、具体的な成果を上げています。
アイデアの壁打ちや情報調査、数式やプログラムの記述など多様な業務で活用されており、全社の生成AI活用を推進するプロジェクトチームを立ち上げて推進していることが特徴です。
オンライン生保のリーディングカンパニーとして、社員の生産性向上によりお客様への顧客体験の一層の向上を目指しています。
製造業での活用事例

製造業では機密データを外部に送信できないため、自社内だけで安全に使える「ローカルLLM」というAI技術が注目されています。BMWグループが導入した「AIconic Agent」はその代表例です。
このシステムは、社内AIプラットフォームで数万社のサプライヤー情報を短時間で比較し、見積もりを迅速に処理できます。10種類の専門的なエージェント(入札書作成や品質監査など)が協力して情報を処理し、効率的に調達業務を支援します。
導入後、入札書の評価にかかる労力を40%削減でき、調達リードタイムを平均2週間も短縮することができました。
月間1,800人が利用し、10,000件もの検索をこなすなど、大規模な運用が可能であり、製造業界でのさらなる普及が期待されています。
印刷業界での活用事例
印刷業界では著作権や特許に関わる機密性の高い情報を扱うため、外部ネットワークを介さない安全なAI活用が求められています。
共同印刷では、完全プライベート型のローカルLLMを導入する実証実験を2025年4月より開始しています。特徴として、LLM利用において外部ネットワークに一切接続せず専用端末内で全処理を完結させる点があります。
完全オフライン環境での稼働により、機密情報漏洩リスクを実質ゼロにしながら、印刷会社の業務特性に合わせたAIモデルをカスタマイズしています。
営業資料の自動生成や顧客対応の効率化を実現し、AIによる営業資料作成時間の30%削減などの効果を見込んでいます。
また、AIの活用により新人社員が業務を迅速に習得できる環境構築も目指しています。
ローカルLLMの導入で直面する課題

ローカルLLMの導入には多くの利点がありますが、いくつかの課題も存在します。特に初めて導入する場合、適切なハードウェア選び、専門知識の習得、モデル管理の負担などが障壁となることがあります。
以下では、ローカルLLM導入時に直面する主な3つの課題について詳しく解説します。
高性能なハードウェアの必要性

ローカルLLMを快適に動作させるには、十分な性能を持つハードウェアが必要です。特に大規模なモデルを動かす場合、高性能なGPUと大容量メモリが不可欠になります。
最低限の動作環境としては、8GB以上のメモリとNVIDIA GTX 1060相当以上のGPUが推奨されます。高度な処理を行うモデルでは、より高性能なGPUとメモリ16GB以上が必要になることもあります。
Macでは Apple Siliconの効率性により比較的軽いモデルなら快適に動作しますが、大規模モデルでは制約があります。スマートフォンでは軽量モデルのみが実用的です。
専門知識の必要性

ローカルLLMの導入には、一定の技術的知識が必要です。コマンドライン操作、Python基礎知識、環境構築の経験などが求められることが多く、初心者にとってはハードルが高い場合があります。
また、モデル選択や最適化設定のためには、AI技術に関する基本的な理解も役立ちます。環境によっては、GPUドライバーの管理や依存ライブラリのインストールなど、システム管理の知識も必要になります。
ただし、最近では直感的な操作が可能なGUIツールも増えており、技術的なハードルは徐々に下がってきています。OllamaやLM Studioなどのツールは、技術知識が少なくても比較的簡単に導入できるように設計されています。
モデルの更新と管理の負担

クラウドサービスと異なり、ローカルLLMではモデルの更新や管理は利用者自身の責任となります。新バージョンの確認、ダウンロード、インストールといった作業が定期的に必要になります。
複数のモデルを使い分ける場合、それぞれの管理やストレージ容量の確保も考慮すべき点です。特に日本語対応モデルは更新頻度が高いことがあり、最新の性能を維持するための管理工数が発生します。
これらの負担を軽減するには、モデル管理機能を持つツールの活用や、更新作業の自動化スクリプトを準備するなどの工夫が効果的です。
おすすめのローカルLLMモデル12選

ローカルLLMの世界は急速に進化しています。企業導入では業務要件に最適なモデル選定が不可欠で、適切な選択が初期投資コストと運用効率を左右します。以下は主要モデルの比較です。
以下の表は、主要なローカルLLMモデルの特徴をまとめたものです。用途や環境に合わせて最適なモデルを選択してください。
| モデル名 | サイズ | 日本語対応 | 必要スペック | 特徴 |
|---|---|---|---|---|
| Llama 3.1 | 8B-70B | 良 | 16GB RAM, GPU 8GB+ | Meta製、最新版のLlamaシリーズ、バランスの良い性能 |
| Gemma 3 | 1B-27B | 優 | 8GB RAM, GPU 4GB+ | Google製、最新モデル、日本語性能が大幅向上、小型サイズでも高性能 |
| Qwen3 | 0.5B-32B / MoE 30B | 優 | 8GB RAM, GPU 4GB+ | Alibaba製、思考能力が向上、30B MoEはリソースを効率的に使用 |
| Mistral Small 3.1 | 24B | 良〜優 | 16GB RAM, GPU 8GB+ | 高速処理(150トークン/秒)と128Kトークンの長文対応。日本語を含む多言語性能が高く、特に多言語理解においてトップクラスの性能を発揮。マルチモーダル(画像理解)にも対応し、軽量化すれば単一GPUでも稼働可能。Apache 2.0ライセンスで商用利用可。 |
| phi-4-deepseek | 14B | 優 | 16GB RAM, GPU 8GB+ | Microsoft/Phi系列の最新版、日本語性能強化 |
| rinna/qwq-bakeneko | 32B | 優 | 32GB RAM, GPU 16GB+ | 日本語特化の大型モデル、Reasoning能力が向上 |
| Swallow | 7B-13B | 優 | 16GB RAM, GPU 6GB+ | 東工大開発の日本語特化モデル、継続的に改良 |
| ELYZA-jp | 7B-13B | 優 | 16GB RAM, GPU 8GB+ | 日本語に特化した高性能モデル、企業利用にも対応 |
| cyberagent/Mistral-Nemo-Japanese | 12B | 優 | 16GB RAM, GPU 8GB+ | サイバーエージェント製、日本語対応Mistralモデル |
| Rinna-3.6B | 3.6B | 優 | 8GB RAM, GPU 4GB | 日本語特化、少ないリソースで高い日本語性能 |
| Gemma 2 | 2B-9B-27B | 良 | 8GB RAM, GPU 4GB+ | Googleの旧モデル、速度と性能のバランスが良い |
| TinyLlama | 1.1B | 可 | 4GB RAM, CPU可 | 超軽量モデル、スマホでも動作可能 |
日本語での利用を重視するなら、Gemma 3、Qwen3、Mistral Small 3.1、rinna/qwq-bakeneko、ELYZA-jpなどの日本語に強いモデルが最適です。限られたリソースでの使用には、Gemma 3の小型版やTinyLlamaなどの軽量モデルが適しています。モバイルデバイスでの実行を考えるなら、特に1B程度の小型モデルを選ぶ必要があります。
2024年後半には日本語性能が大幅に向上したモデルが続々と登場し、企業での実用レベルに達しています。特にGoogle Gemma 3シリーズやAlibabaのQwen3シリーズ、Mistral社のMistral Small 3.1は、少ないリソースでも高い性能を発揮します。Mistral Small 3.1は特に東アジア言語(日本語・中国語・韓国語)での性能が高く、128Kトークンという長文処理能力を持ち、高速処理(1秒あたり150トークン)が可能なため、長文資料の分析や多言語対応システムの構築に適しています。
ローカルLLMの作り方・構築手順
企業導入の成功には、IT部門が理解すべき構築プロセスの把握が重要です。以下の手順はプロジェクト計画策定や技術要件の理解に役立ち、外部ベンダーとのコミュニケーションも円滑にします。
ローカルLLMの構築は、適切な手順に従えば技術チームでも効率的に実現可能です。ここでは、環境準備からモデル実行までの一般的な構築手順を5つのステップで解説します。
自社環境に合わせた最適な設定ができるよう、各ステップの詳細を確認しましょう。
環境準備

ローカルLLM構築の第一歩は、適切なハードウェア環境を整えることです。各OSごとの推奨スペックは以下の通りです。
【Windows環境】
- CPU: 最低4コア以上
- RAM: 16GB以上(大規模モデル用には32GB以上)
- GPU: NVIDIA GPU(VRAM 6GB以上)推奨
- ストレージ: SSDの空き容量20GB以上
【Mac環境】
- Apple Silicon搭載Mac (M1/M2/M3シリーズ)
- RAM: 16GB以上
- ストレージ: SSDの空き容量20GB以上
【Linux環境】
- CPU: 4コア以上
- RAM: 16GB以上
- GPU: NVIDIA GPU(CUDA対応)
- ストレージ: SSDの空き容量20GB以上
モデルのサイズや用途によって必要なスペックは変わるため、導入予定のモデルの要件を事前に確認しておくことが重要です。
LLM実行フレームワークのインストール

環境準備ができたら、次はLLM実行フレームワークのインストールを行います。主要なフレームワークには以下の2つがあります。
オプション1: llama.cpp (各プラットフォーム対応)
【Windowsの場合】
# Gitのインストール (まだの場合)
winget install --id Git.Git
# リポジトリのクローン
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# ビルド (Visual Studioのコマンドプロンプトで実行)
cmake .
cmake --build . --config Release
【Macの場合】
# Homebrewを使用してツールをインストール
brew install cmake
# リポジトリのクローン
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# ビルド
mkdir build && cd build
cmake ..
make -j4
【Linuxの場合】
# 必要なパッケージをインストール
sudo apt update
sudo apt install -y build-essential cmake
# リポジトリのクローン
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# ビルド
mkdir build && cd build
cmake ..
make -j$(nproc)
オプション2: Ollama (オールインワンソリューション)
【Windowsの場合】
- Ollama公式サイトからインストーラーをダウンロード、実行
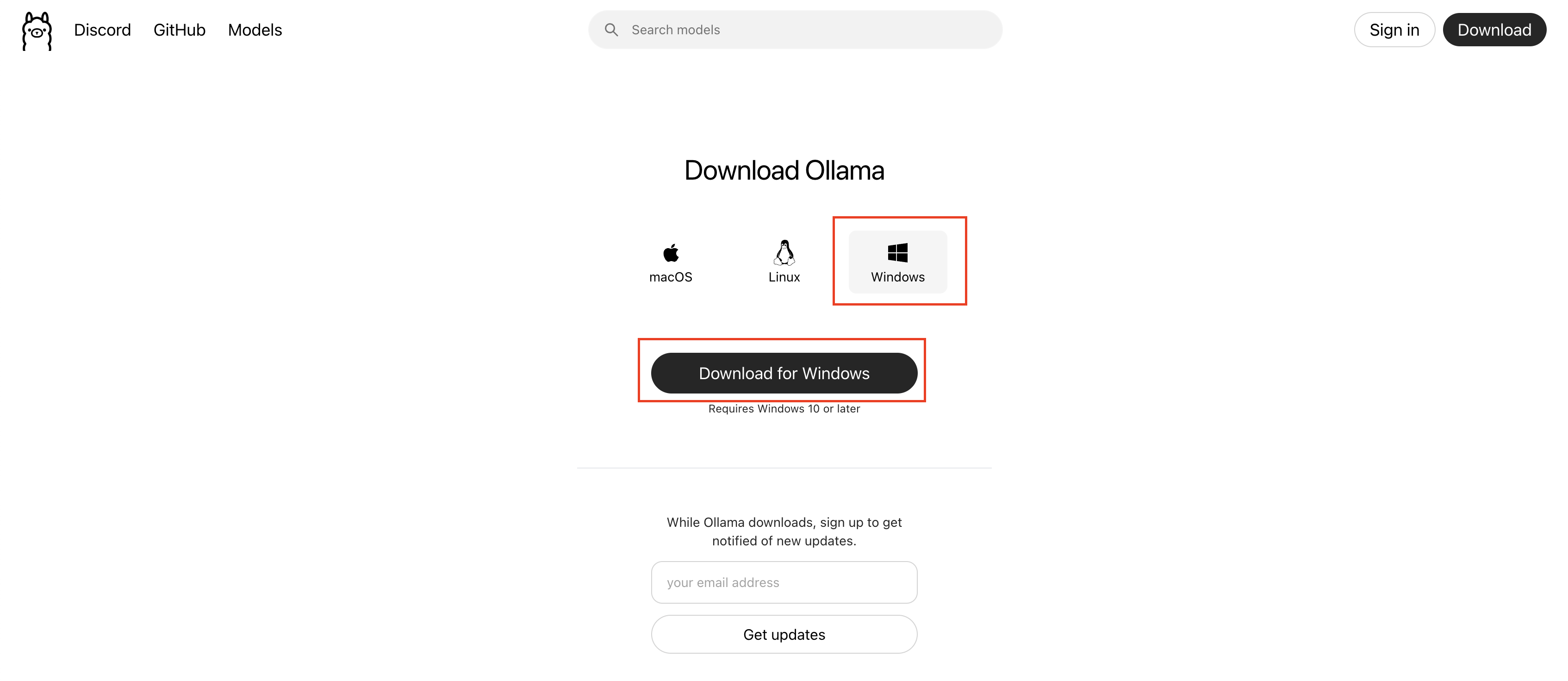
【Macの場合】
brew install ollama
【Linuxの場合】
curl -fsSL https://ollama.ai/install.sh | sh
Ollamaは操作が直感的でインストールが簡単なため、初心者には特におすすめです。
モデルのダウンロード・管理

フレームワークのインストール後、実際に使用するモデルをダウンロードします。
【llama.cppの場合】
GGUF形式のモデルをHuggingFaceなどからダウンロードします。
# llama.cppのディレクトリで実行
curl -L https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/resolve/main/mistral-7b-instruct-v0.1.Q4_K_M.gguf -o models/mistral-7b-instruct-v0.1.Q4_K_M.gguf
【Ollamaの場合】
コマンド一つでモデルをダウンロードできます。
# Mistral 7Bモデルをダウンロード
ollama pull mistral
# Llama 2 7Bモデルをダウンロード
ollama pull llama2
モデルのサイズによってはダウンロードに時間がかかることがあります。安定したネットワーク環境で実行しましょう。
Webインターフェース(オプション)

コマンドライン操作に慣れていない場合は、WebUIの導入が便利です。主な選択肢は以下の2つです。
【オプション1: llama.cpp + web UI (text-generation-webui)】
インストール手順
# リポジトリをクローン
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
# 必要なパッケージをインストール
pip install -r requirements.txt
# webUIの起動 (llama.cppバックエンドを使用)
python server.py --model /path/to/your/model.gguf --loader llama.cpp
【オプション2: Ollama + Web UI】
Dockerを使用する場合
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:main
WebUIを導入することで、ChatGPTのような使いやすいインターフェースでローカルLLMを操作できるようになります。
モデルの実行と推論

すべての準備が整ったら、モデルを実行して会話を始めることができます。
【llama.cppでの実行例】
# llama.cppディレクトリで
./main -m models/mistral-7b-instruct-v0.1.Q4_K_M.gguf -n 256 -p "こんにちは、あなたの名前は?"
パラメータの説明:
-m: モデルファイルのパス-n: 生成するトークン数-p: プロンプト(質問や指示)
【Ollamaでの実行例】
# 基本的な使用法
ollama run mistral "こんにちは、あなたの名前は?"
# パラメータ付きの実行
ollama run mistral --temperature 0.7 "京都で人気の観光スポットを5つ教えてください。"
【APIを使用した実行例】
curl -X POST http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "こんにちは、あなたの名前は?",
"stream": false
}'
モデルの応答性はハードウェア性能に依存します。温度(temperature)や生成トークン数などのパラメータを調整して、最適な設定を見つけることが重要です。
デバイス別ローカルLLMの実行方法

企業のローカルLLM活用では社内IT環境との整合性が重要です。様々な社内デバイス(PC・サーバー・モバイル端末)での実行方法を理解することで、最適な導入計画を立てることができます。
ローカルLLMは様々な機器で実行可能ですが、機器によって最適な設定と選択すべきモデルが異なります。ここでは、企業内の主要デバイスでの実行方法について解説します。
PC(Windows / macOS / Linux)で実行する際のポイント
PCでのローカルLLM実行は最も一般的で、選択肢も豊富です。
Windowsでの実行では、WSL2(Windows Subsystem for Linux)を利用する方法とネイティブアプリケーションを使用する方法があります。WSL2を使うとLinux環境の豊富なツールが使えますが、初心者にはOllamaなどのネイティブアプリケーションがおすすめです。
macOSでの実行では、Apple SiliconチップのMetalフレームワークを活用することで、専用GPUがなくても効率的に処理できます。M1以降のチップでは、7B程度のモデルなら比較的快適に動作します。
Linuxでの実行は最も自由度が高く、NVIDIA GPUの性能を最大限に活用できます。上級者向けのカスタマイズオプションも豊富です。
初心者に適したグラフィカルアプリケーションとしては、LM Studio、Ollama、KoboldCPPなどが人気です。これらは直感的なインターフェースで操作できるため、コマンドラインに慣れていなくても利用しやすいでしょう。
モバイルデバイス(iOS / Android)で実行する際のポイント

モバイルデバイスでもローカルLLMの実行が可能になっています。
iOSでは「Llama in Your Pocket」や「Mantis」などのアプリが利用可能です。これらのアプリは、小型のLLMモデルをiPhone/iPad上で直接実行できます。
Androidでは「MLC LLM」や「Llama 2 Turbo」などのアプリが提供されています。特にGoogleのPixelシリーズなど、高性能なスマートフォンではより大きなモデルの実行も可能です。
モバイルデバイスでローカルLLMを実行する場合の注意点:
- モデルサイズ: 多くの場合、1B〜2B程度の小型モデルが推奨されます。最新の高性能スマートフォンでは7Bクラスのモデルも動作しますが、バッテリー消費が激しくなります。
- バッテリー消費: 推論処理は電力を多く使用するため、バッテリー残量に注意が必要です。長時間使用する場合は充電しながらの使用がおすすめです。
- 発熱: 処理負荷によって端末が熱くなる場合があります。過度な発熱を防ぐため、ケースを外すなどの対策も効果的です。
モバイルデバイスでのローカルLLM活用は、移動中や急な質問に対応したい場合など、クラウドサービスが使えない状況で特に役立ちます。
まとめ

ローカルLLMは、プライバシー保護、コスト削減、カスタマイズ性向上という大きなメリットを提供する技術です。自分の機器内で完結するため、機密情報を扱う業務や個人情報を守りたい場合に特に有効です。
導入には一定のハードウェア要件と技術的知識が必要ですが、Ollamaなどの使いやすいツールの登場により、導入のハードルは低くなっています。
日本語対応モデルも充実しており、Gemma 3、Qwen3、Mistral Small 3.1、rinna/qwq-bakeneko、ELYZA-jpなどの日本語に強いモデルが実用的な性能を持っています。限られたリソースではGemma 3の小型版やTinyLlamaなどの軽量モデルが適しています。
ローカルLLMの世界は急速に発展しており、今後さらに使いやすく高性能なモデルやツールが登場するでしょう。自分の環境と目的に合ったモデルを選び、AIの可能性を最大限に活用していきましょう。
おわりに:企業導入のポイントと展望
ローカルLLMの企業導入は、情報セキュリティと業務効率化を両立させる有効な手段です。実際に導入を検討する企業が増える中、計画的な準備と専門的なサポートが成功の鍵となります。
導入時のポイント
ローカルLLM導入を成功させるためには、以下のポイントに注意することが重要です:
- 明確な活用目的の設定:単なる技術導入ではなく、具体的な業務課題解決のためのツールとして位置づけましょう。
- 段階的な導入計画:一度に全社導入するのではなく、小規模な実証実験から始め、効果を確認しながら拡大していくことをおすすめします。
- 適切なモデル選定:業務内容や必要な機能、日本語対応レベルなどを考慮した適切なモデル選定が重要です。専門家のアドバイスを受けることで、最適な選択が可能になります。
- 社内教育の実施:導入後の活用を促進するため、利用者向けの教育やサポート体制を整えましょう。
企業導入の展望
ローカルLLMの企業利用は今後ますます拡大し、以下のような展開が予想されます:
- 専門分野特化型の増加:特定業界や業務に特化したカスタムモデルの登場
- 導入支援サービスの充実:経験豊富な専門家による導入支援や運用保守サービスの拡大
- クラウド・ローカルのハイブリッドモデル:機密データはローカル処理、一般的な処理はクラウドで行うなどの使い分け
ローカルLLMの導入には専門的な知識が必要な場面も多く、経験豊富な専門家のサポートを受けることで、スムーズな導入と効果的な活用が可能になります。特にセキュリティ要件の高い業界や、独自のカスタマイズが必要な場合は、専門家への相談が効果的です。
当社ではローカルLLMの導入から運用までをトータルでサポートしています。貴社の課題やニーズに合わせた最適なソリューション提案が可能ですので、まずはお気軽にご相談ください。