Ollamaの使い方・対応モデル・動作環境を徹底解説|日本語LLMや商用利用の最新情報も紹介
大規模言語モデル(LLM)をローカル環境で手軽に扱えるツールとして注目されているのが「Ollama」です。
2025年7月30日にチャットUI機能が追加され、従来のCLI操作に加えて初心者でも使いやすいグラフィカルインターフェースが利用可能になりました。
本記事では、Ollamaの概要から最新のチャット機能、対応モデル、日本語特化モデル、導入・使い方、商用利用の可否までを網羅的に解説します。
また、弊社ではマッキンゼーやGAFA出身のAIエキスパートがAI導入に関する無料相談を承っております。
無料相談は先着20社様限定で「貴社のAI活用余地分析レポート」を無償でご提供するキャンペーンも実施中です。
ご興味をお持ちの方は、以下のリンクよりご連絡ください:
AI導入に関する無料相談はこちら
資料請求はこちら

AI導入.comを提供するビルドAI株式会社 代表取締役。トロント大学コンピューターサイエンス学科卒業。株式会社ANIFTYを創業後、世界初のブロックチェーンサービスを開発し、東証プライム上場企業に売却。その後、マッキンゼー・アンド・カンパニーにコンサルタントとして入社。マッキンゼー日本オフィス初の生成AIプロジェクトに従事後、ビルドAI株式会社を創業。

Ollamaとは

Ollamaは、ローカル環境で大規模言語モデル(LLM)を簡単にセットアップし、実行できるようにするオープンソースツールです。
開発者は、複雑な設定を行うことなく、自身のコンピュータ上でLlama 3.3、DeepSeek R1、Gemma 3などの様々な最新LLMを手軽に試すことができます。
2025年7月30日の大型アップデートにより、従来のコマンドラインインターフェース(CLI)に加えて直感的なチャットUIが追加されました。この新機能により、初心者でもChatGPTのような使い慣れたインターフェースでAIモデルとの対話が可能です。
また、REST APIも提供されているため、他のアプリケーションとの連携も容易で、プライベートな環境でのAI開発や実験が促進されます。
Ollamaで使えるモデル一覧

Ollamaでは、Meta、Google、Microsoft、Mistral AI、Alibabaなど、世界の主要なAI開発企業や研究機関が提供する多様な大規模言語モデルを利用できます。
オープンソースとして公開されている多くの人気モデルがサポートされており、簡単なコマンドでダウンロードしてすぐに使い始めることが可能です。
Llama 3.3(Meta製)
Llama 3.3はMetaが2025年に発表した最新のオープンソースモデルです。
1B、3B、8B、70Bまでのサイズバリエーションがあり、特に8Bモデルはコンパクトながら高い性能を発揮します。
コンテキスト長は最大128Kトークンをサポートし、コーディング、推論、創造的文章生成など幅広いタスクに対応しています。
Mixture of Experts(MoE)アーキテクチャを採用し、効率的な推論処理を実現しており、商用利用も可能な柔軟なライセンスでOllamaでの人気モデルの一つです。
DeepSeek R1(DeepSeek社製)
DeepSeek R1は2025年1月に中国のDeepSeek社がリリースした推論特化モデルで、科学技術分野での高い性能が特徴です。
1.5B、7B、8B、32B、671Bの各サイズが提供され、特にコーディングや複雑な推論タスクで業界トップクラスの性能を示します。
Chain-of-Thought(思考の連鎖)推論機能を内蔵し、段階的な問題解決プロセスを可視化できるため、数学的問題解決や論理的推論で特に優れた能力を発揮します。
コンテキスト長は最大128Kトークンに対応し、英語だけでなく中国語や日本語にも対応した多言語版もOllamaで利用可能です。

Gemma 3(Google製)
Gemma 3は2025年3月にGoogleが発表した軽量で高性能なオープンソースモデルです。
2B、9B、27Bのサイズバリエーションが提供され、特に小型の2Bモデルは限られたリソースでも良好な性能を発揮します。
マルチモーダル対応版(Gemma 3-VL)も提供されており、画像と文章を同時に処理できる能力を持ちます。Googleの最新技術の恩恵を受けており、教育目的や個人利用、小規模ビジネスに適した選択肢です。
コンテキスト長は最大256Kトークンをサポートし、商用利用も許可されています。
Phi-4(Microsoft製)
Phi-4はMicrosoftが開発した効率重視のモデルで、小型ながら優れた推論能力を持ちます。
特に最新の4K(4000パラメータ)モデルは、最小限のリソースで驚くべき性能を発揮します。
コーディング、論理的推論、一般的な質問応答など幅広いタスクに対応し、教育利用や小規模デバイスでの実装に最適です。
コンテキスト長は8Kトークンをサポートしています。
Qwen 3(アリババ製)
Qwen 3はアリババが開発した多言語対応モデルで、英語と中国語に特に強みがあります。
1.5B、7B、14B、72Bのサイズバリエーションがあり、パラメータ数に応じて性能と要求リソースのバランスを取れます。
コンテキスト長は最大32Kトークンで、コーディング、文章生成、質問応答など様々なタスクに対応します。
商用利用も可能なライセンスを採用しています。

Mistral(Mistral社製)
MistralモデルはフランスのスタートアップであるMistral AI社が開発したモデルで、効率性と性能のバランスに優れています。
7B、8x7B(Mixtral)、8B-Instruct等のバリエーションがあり、特にMixtralはMoE(Mixture of Experts)アーキテクチャを採用して効率的な推論を実現しています。
コーディング能力に優れ、32Kトークンのコンテキスト長をサポートしています。
Elyza-7B(日本語対応モデル)
Elyza-7Bは日本のAI企業ELYZAが開発した日本語に特化したモデルです。
Llama 2をベースに日本語能力を大幅に強化しており、日本語での文章生成、要約、質問応答などのタスクで高い性能を発揮します。
7Bパラメータのモデルサイズで、日本語コンテンツを扱う場合に最適な選択肢の一つです。
商用利用も可能なライセンスを採用しています。
Ruri(日本語Embedding特化モデル)
Ruriは名古屋大学が開発した日本語Embedding(文章の数値表現)に特化したモデルです。
文書の類似度計算や検索、クラスタリングなどのタスクに最適化されています。
他のLLMと組み合わせることで、日本語文書の検索・参照機能を強化できます。
軽量で高速な処理が可能なため、リソースが限られた環境でも効果的に利用できます。
Ollamaの日本語対応モデル

Ollamaでは、グローバルなモデルだけでなく、日本語の処理に特化したり、日本語性能を高めたりした様々な大規模言語モデルも手軽に利用できます。
これにより、日本のユーザーや開発者は、自身のローカル環境で日本語を用いたAI開発や実験を効率的に進めることが可能です。
Llama-3-ELYZA-JP-8B(ELYZA製・日本語特化)
Llama-3-ELYZA-JP-8Bは、Meta社の高性能モデルLlama 3 8Bをベースとして、株式会社ELYZAが日本語能力を強化・チューニングしたモデルであり、Ollamaで利用できます。
ELYZA社が持つ日本語処理技術やデータセットを活用し、特に日本語での対話性能や読解力、文章生成能力を高めています。
オリジナルのLlama 3が持つ高い基本性能を引き継ぎつつ、日本のユーザーにとってより使いやすく、自然な応答が可能なモデルとなっています。
suzume-llama-3-8B-japanese(Lightblue製・会話特化)
suzume-llama-3-8B-japaneseは、株式会社LightblueがMetaのLlama 3 8Bを基に開発した、特に日本語の自然な会話能力に焦点を当ててファインチューニングしたモデルであり、Ollamaで利用可能です。
日本の文化や話し言葉のニュアンスを理解し、より人間らしい、親しみやすい対話応答を生成することを目指しています。
チャットボットや対話型AIアシスタントなど、インタラクティブな用途での活用が期待されます。

DeepSeek-R1 日本語拡張版(DeepSeek製・多言語→日本語拡張)
DeepSeek-R1の日本語拡張版は、元々多言語対応であるDeepSeekモデルの日本語処理能力をさらに向上させたバージョンであり、Ollamaで利用できます。
DeepSeekモデルはコーディング能力が高いことで知られていますが、この拡張版では日本語の理解力や生成能力も強化されており、技術的な文書作成や日本語でのプログラミングに関する質問応答などで高い性能を発揮することが期待されます。
多言語モデルの強みを活かしつつ、日本語タスクへの適応性を高めています。
Gemma2-2b-jpn(Google製・軽量日本語モデル)
Gemma2-2b-jpnは、Googleが開発したGemma 2ファミリーの中で、比較的小規模な2B(20億パラメータ)サイズでありながら日本語性能を高めたモデルであり、Ollamaで利用できます。
Gemma 2は前世代に比べて性能が向上しており、この日本語版モデルは軽量であるため、メモリや計算資源が限られた環境でも動作させやすい利点があります。
日本語でのテキスト生成、要約、質疑応答などのタスクを手軽に試したい場合に適しています。
Ruri(名古屋大学製・日本語embedding特化)
Ruriは、名古屋大学の研究グループなどが開発した、日本語テキストの分散表現(Embedding)生成に特化したモデルであり、Ollamaの embeddings 機能で利用できます。
このモデルは、単語や文章を意味的な特徴を捉えたベクトル空間上の点に変換することに特化しており、類似文書検索、テキスト分類、クラスタリングなどの応用に使われます。
一般的な対話型LLMとは異なり、意味ベクトルを生成することが主目的です。
Ollamaの使い方【5ステップ】

2025年7月の大型アップデートにより、Ollamaの使い方は大幅に簡単になりました。従来のコマンドライン操作に加えて、直感的なチャットUIが利用できるようになったため、初心者でも手軽にローカル環境でLLMを動かす体験ができます。
基本的な使い方は5つのステップに分けることができます。
1. インストール
Ollamaのインストールは、各OS向けに用意された方法で簡単に行えます。
macOSとWindowsの場合は、**Ollamaの公式サイト(https://ollama.com/)からインストーラーをダウンロードして実行**するのが最も手軽です。インストールすると自動的に最新の**チャットUI機能**も含まれます。
Linuxの場合は、ターミナルで curl -fsSL https://ollama.com/install.sh | sh というコマンドを実行するだけでインストールが完了します。
また、macOSユーザーはHomebrewを使って brew install ollama コマンドでもインストール可能です。
Dockerを利用している場合は、docker pull ollama/ollama で公式イメージを取得し、コンテナとして実行することもできます。

2. チャットUIの起動【推奨】
2025年7月の最新アップデートにより、初心者でも使いやすいグラフィカルなチャットUIが利用できるようになりました。
macOSの場合は、メニューバーのOllamaアイコンから「Open Ollama」を選択するだけでチャットUIが起動します。
Windowsの場合は、システムトレイのOllamaアイコンから同様に起動できます。
起動されるインターフェースはChatGPTのような親しみやすいデザインで、サイドバーにはチャット履歴、画面右下にはモデル選択機能があり、直感的に操作できます。
ファイルのドラッグ&ドロップにも対応しており、PDF、テキストファイル、プログラムコード、画像などを直接チャットウィンドウに投げ込んで解析させることができます。
3. モデルの選択と利用
チャットUIを使用する場合は、画面右下のモデル選択ドロップダウンから使用したいモデルを選択するだけです。初回選択時は自動的にモデルのダウンロードが開始されます。
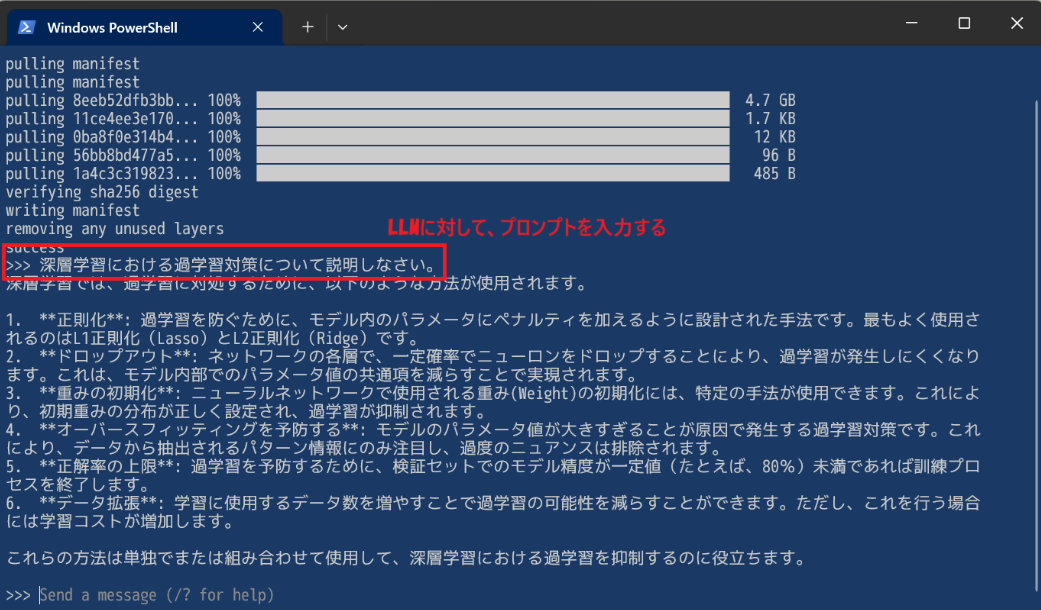
コマンドラインを使用する場合は、ターミナルで ollama run <モデル名> コマンドを実行します。例えば、最新のLlama 3.3の8Bモデルを使いたい場合は ollama run llama3.3 と入力します。
導入済みのモデル一覧は ollama list で確認でき、不要になったモデルは ollama rm <モデル名> で削除できます。モデルのダウンロードのみを事前に行いたい場合は ollama pull <モデル名> を使います。
初回はモデルデータのダウンロードが始まり、完了すると対話可能な状態になります。
4. 高度な機能の活用
マルチモーダル対応により、対応モデル(Llama 3.3、Gemma 3-VL、Qwen 2.5-VLなど)では画像解析も可能です。画像ファイルをチャットウィンドウにドラッグ&ドロップするだけで、画像の内容について質問できます。
ファイル処理機能では、PDFドキュメント、プログラムコード、テキストファイルなどを直接読み込ませて、内容に関する質問や要約、解析を依頼できます。
チャット履歴管理により、過去の対話を保存・参照でき、継続的なプロジェクト作業に便利です。
5. 拡張機能との連携
公式チャットUIに加えて、さまざまなサードパーティ製ツールとの連携も可能です。
例えば、「Open WebUI」などのWebインターフェースを使えば、ブラウザ上でより高度なモデル管理やRAG(検索拡張生成)機能を利用できます。
VSCodeなどのコードエディタ向け拡張機能も多数開発されており、コーディング支援にOllamaを統合して利用できます。
REST APIも提供されているため、独自のアプリケーション開発や他のツールとの連携も容易に実現できます。
Ollamaの動作環境【OS別の特徴】

Ollamaは複数のOS環境でサポートされており、ハードウェア構成によって性能が大きく異なります。
それぞれの環境特性を理解することで、最適なパフォーマンスを引き出すことができます。
CPU利用時の特徴
CPU環境でのOllama利用は、最低限のスペックとしては4コア以上のCPUと8GB以上のRAMが推奨されます。
小型モデル(2B〜7B)であれば一般的なラップトップでも動作可能ですが、レスポンス速度は限定的です。
特にIntel/AMDのx86_64アーキテクチャでは最新のAVX-512命令セットを持つCPUで最適化されています。
AppleシリコンではM1/M2/M3チップの神経エンジンを活用でき、従来のCPUより高速な推論が可能です。
メモリ使用量はモデルサイズに比例し、1Bあたり約2GBのRAMを消費するため注意が必要です。
GPU利用時の特徴
GPU環境ではOllamaの性能が大幅に向上します。
特にNVIDIA GPUでは6GB以上のVRAMを持つGPUが推奨され、RTX 3060以上のミドルレンジGPUがあれば7B〜14Bクラスのモデルをスムーズに動作させられます。
大規模モデル(30B以上)には16GB以上のVRAMを搭載した高性能GPUが必要です。CUDAとcuDNNが自動インストールされるため、追加設定は不要です。
AMDのGPUはLinux環境でROCm経由でサポートされていますが、Windowsでは対応が限定的です。
GPU環境では推論速度が10〜100倍向上し、より大きなコンテキスト窓サイズでの処理も可能になります。
Ollamaのバージョンアップ手順【環境別】

Ollamaは定期的にアップデートがリリースされ、新機能の追加やパフォーマンスの改善が行われています。
環境ごとに適切なバージョンアップ手順を実施することで、常に最新の状態を維持できます。
公式インストーラー/スクリプトで導入した場合
Windowsでは、公式サイトから最新のインストーラーをダウンロードして実行するだけで上書きインストールされます。
Linuxでは公式スクリプトを再度実行することで最新バージョンにアップデートできます。
curl -fsSL https://ollama.com/install.sh | sh
更新前にOllamaプロセスを停止する必要があるため、実行中のOllamaセッションやサービスをすべて終了してからアップデートを実行してください。
macOS(Homebrew経由の場合)
まず brew updateコマンドで Homebrew 自体を最新の状態にします。
次に brew upgrade ollamaを実行すると、Ollamaが最新バージョンにアップグレードされます。
Homebrewはパッケージの依存関係も自動的に管理するため、関連するコンポーネントも適切に更新されます。
更新前に必ずOllamaのプロセスを終了させてから行ってください。

Docker環境の場合
まず docker pull ollama/ollama:latestコマンドで最新のOllamaイメージをダウンロードします。
次に既存のコンテナを停止・削除し、新しいイメージを使用して再度コンテナを起動します。
モデルデータを保持するためには、適切なボリュームマウントを設定することが重要で、以下のようにボリュームを指定してコンテナを起動することで、モデルデータを保持したままバージョンアップが可能です。
docker run -d -v ollama_data:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:latest
バージョンアップ後の確認
ollama --versionコマンドを実行し、表示されるバージョン番号が期待する最新バージョンと一致していることを確認します。
またollama listコマンドで既存のモデルが正常に認識されていることも確認してください。
新バージョンでの機能変更点は公式GitHubリポジトリのリリースノートで確認できます。
もし問題があれば、ログファイル(通常は~/.ollama/logsディレクトリ内)を確認することで詳細な情報を得られます。
Ollamaは商用利用できる?

Ollama自体はMITライセンスで公開されており、完全に商用利用可能です。2025年7月の最新バージョンでも引き続きMITライセンスが適用されています。
ただし重要なのは、Ollamaで利用する各AI言語モデルのライセンスは個別に確認する必要がある点です。
商用利用可能な主要モデル:
- Llama 3.3 - Meta Community License(商用利用可能)
- Gemma 3 - Gemma Terms of Use(商用利用可能)
- DeepSeek R1 - Apache 2.0ライセンス(商用利用可能)
- Mistral - Apache 2.0ライセンス(商用利用可能)
- Qwen 3 - Tongyi Qianwen License(商用利用可能)
日本語特化モデルについても、ELYZA-JP-8B、suzume-llama-3-8B-japaneseなど多くが商用利用可能なライセンスを採用しています。
商用利用を検討する場合は、使用する具体的なモデルの公式ライセンス条項を必ず確認し、月間アクティブユーザー数などの制限事項がある場合は遵守してください。
ローカルLLMを使用する際のメリットやビジネスへの活用法・実際の導入事例については下記の記事をご覧ください。
まとめ

Ollamaは2025年7月の大型アップデートにより、ローカル環境で大規模言語モデルを手軽に実行できる最も優れたプラットフォームの一つとなりました。
新しいチャットUI機能により初心者でも直感的に利用でき、ファイルのドラッグ&ドロップ機能やマルチモーダル対応により、より幅広い用途での活用が可能になっています。
今後もDeepSeek R1やGemma 3などの最新モデルの追加、さらなる機能強化が期待される中、自分の目的や環境に合わせたモデル選択と最適な設定で、プライバシーを確保しながら高性能なAI機能をローカルで活用してみてください。