【完全版】RAGとは?仕組み・導入方法・活用事例を解説
生成AIの正確性や最新情報の活用に課題を感じる企業は少なくありません。
特に、データ分析や市場調査では、リアルタイムの情報を活用し、精度の高い意思決定が求められます。
そのようなAIの精度的課題の解決策として「RAG」という技術が非常に注目されています。
本記事では、RAGの仕組み、導入メリット、活用事例、実装方法を解説します。
また、弊社ではマッキンゼーやGAFA出身のAIエキスパートがAI導入に関する無料相談を承っております。
無料相談は先着20社様限定で「貴社のAI活用余地分析レポート」を無償でご提供するキャンペーンも実施中です。
ご興味をお持ちの方は、以下のリンクよりご連絡ください:
AI導入に関する無料相談はこちら
資料請求はこちら

RAGとは
ImageFXで作成
RAG(Retrieval-Augmented Generation、検索拡張生成)とは、特定の参照情報をもとに大規模言語モデル(LLM)の出力を最適化する手法です。
モデルが回答を生成する前に、社内データのような信頼できるデータベースの新情報を参照することで、信頼性の高い出力を行うことができます。
従来の生成AIは、学習時点の情報のみをもとに出力を行うため、最新の情報や企業固有のデータを反映しにくいという課題がありました。
こうした課題を補う手法として注目されているのがRAGです。
生成AIとRAGの違い
最大の違いは、RAGが外部データを参照できるのに対し、生成AIは学習済みデータのみで出力する点です。
生成AIは、学習時点の情報に基づいて回答を生成するため、新しい情報の反映が難しい傾向があります。
一方、RAGは、社内データや最新情報をリアルタイムで検索し、内容に反映。
文脈に沿った、信頼性の高い回答が可能です。
RAGの活用分野
RAGは、専門性が求められる分野で特に有効であり、従来の生成AIでは難しかった最新情報の活用を可能にしています。
主な活用分野は以下の通りです:
- カスタマーサポート: FAQの自動回答、チャットボットの精度向上
- 医療: 最新の医学論文・診療ガイドラインの検索
- 法務: 契約書・法律データベースを活用したアドバイス生成
- 金融: 市場ニュースや財務データを基にした投資分析
- 教育: 学習支援・教材検索によるパーソナライズ学習
RAGシステムの構造
ImageFXで作成
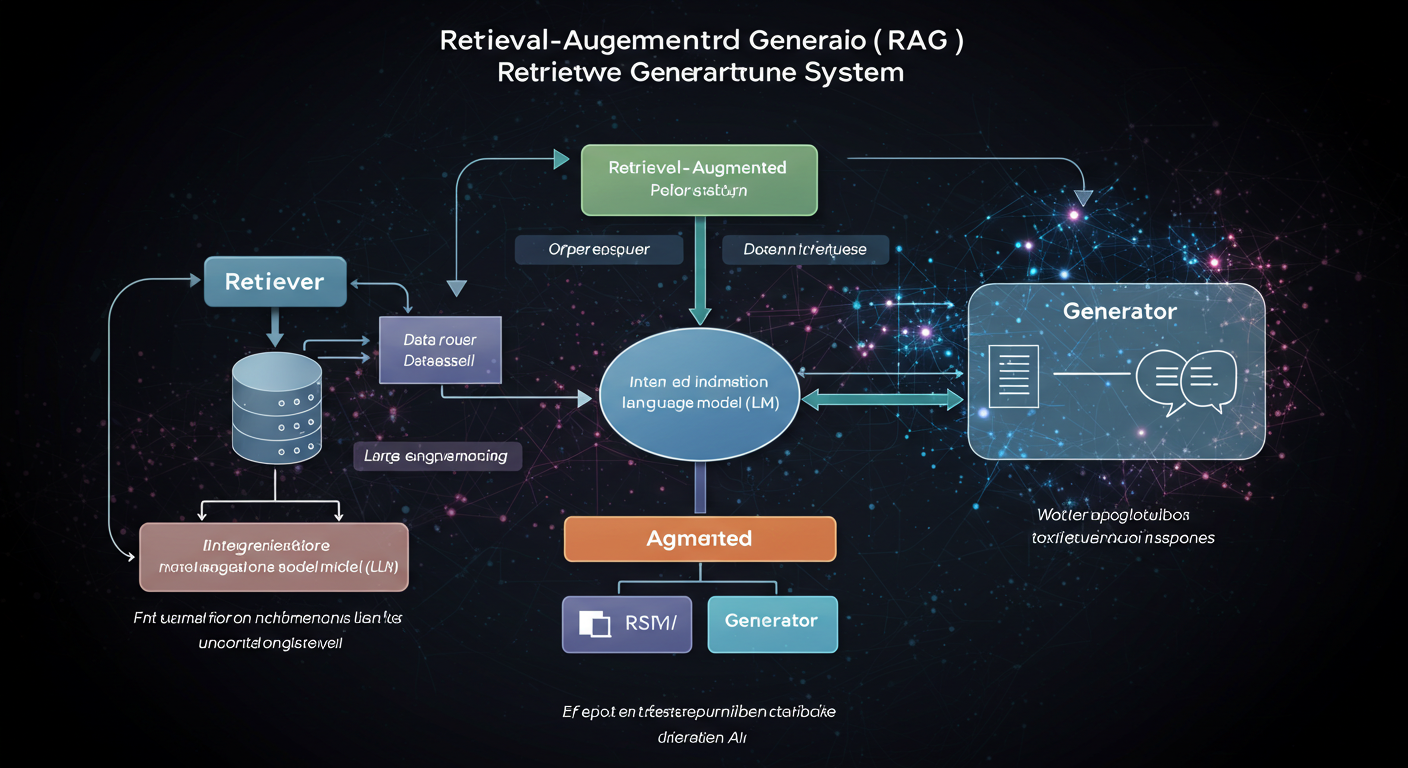
RAGシステムは、検索(Retriever)、拡張(Augmented)、生成(Generator)の3つの機能で構成されています。
これらが連携することで、外部データを活用しながら正確な情報提供が可能です。
ここからは、それぞれの役割について詳しく解説します。
検索(Retriever)機能の役割
検索機能は、ユーザーのクエリに関連する情報を外部データベースから取得する役割です。
RAGの処理の第一段階となるため、この機能の精度がテキスト生成の質を左右します。
検索技術には、ベクトル検索や全文検索が用いられ、適切な情報を効率的に抽出することが可能です。
検索精度が低いと、生成AIが不正確な回答を出すリスクが高まるため、関連性の高い情報を正しく取得することが重要です。
拡張(Augmented)機能の役割
拡張機能は、検索結果をフィルタリングし、生成モデルに最適なコンテキストを提供する役割です。
検索されたデータには、不要な情報や関連性の低いデータが含まれる場合があります。
拡張機能では、それらを適切に整理し、最も関連性の高い情報のみを抽出することで、生成AIが適切な回答を作成できるようにサポートします。
この段階で情報を適切に整理することで、誤った情報が組み込まれるリスクを減らし、より精度の高い応答が可能です。
生成(Generator)機能の役割
生成機能は、拡張機能によって提供された情報をもとに、自然なテキストを生成する役割です。
この段階では、大規模言語モデル(LLM)が活用され、ユーザーのクエリに対して最適な回答が作成されます。
適切なコンテキストと十分な情報量があるほど、より精度の高い生成が可能です。
検索・拡張機能と適切に連携することで、ユーザーにとって有益で信頼性の高い情報提供が実現します。
RAGとファインチューニングの違い
ImageFXで作成
RAGとファインチューニングは、AIモデルの知識を拡張・更新するための異なる手法です。
RAGは外部データを検索してリアルタイムで情報を取り入れるのに対し、ファインチューニングは特定のタスクやドメイン向けにモデルを再学習させることで適応させます。
ここからは、知識の更新方法、リソース要件、適用範囲において、RAGとファインチューニングを徹底比較します。
知識の更新方法
RAGは、外部データベースの更新だけで最新の情報を反映できるため、再学習は不要です。
一方、ファインチューニングは知識更新に再学習が必要で、時間や計算コストがかかります。
情報の即時性を求める場面では、RAGの方が効率的です。
リソース要件
RAGを導入する企業は、比較的少ないリソースで運用できる点がメリットです。
検索システムを利用する構造のため、処理が軽量でコストも抑えられます。
一方で、ファインチューニングを行う企業は、大量の学習データや高性能GPUなどの計算資源が必要となり、導入や運用に多くのコストがかかります。
限られた予算やリソースでAIを活用したい場合は、RAGの方が適した選択肢といえます。
適用範囲
RAGは、幅広い情報に対応できる汎用型です。
一般的な質問応答や最新情報の提供に適しており、さまざまな業務に活用できます。
一方、ファインチューニングは、特定の業界や企業向けに最適化されたモデルを構築できるため、専門性の高い業務やプロセス向きです。
汎用性を重視するならRAG、特化型の精度を求めるならファインチューニングの選択が適しています。
RAGに適したデータ管理方法
ImageFXで作成
RAGの効果的な運用には、データの質と検索効率を最大化するための適切なデータ管理が不可欠です。
検索結果の精度を向上させるには、関連性の高いデータを適切に処理し、最新の情報を維持することが重要になります。
ここからは、データ準備、ベクトル化とインデックス化、データのメンテナンスと更新について詳しく解説します。
データ準備
RAGの精度を高めるには、事前のデータ整理が不可欠です。
関連性の高い情報を収集し、検索しやすい形式に整えることが重要です。
FAQやマニュアル、技術文書などの社内データを整理し、フォーマットを統一。
不要な情報の削除や表記の揺れをなくすクリーニングも必要です。
データの質が低いと、検索結果や回答の精度に悪影響が出るため、準備段階がRAG運用の成否を左右します。
データのベクトル化とインデックス化
RAGの精度と速度を高めるには、データのベクトル化とインデックス化が欠かせません。
テキストを数値ベクトルに変換し、高速な検索を可能にします。
FAISS(高速な類似データ検索)やElasticsearch(全文・ベクトル検索対応)を使うことで、クエリに近い情報を効率よく素早く取得できます。
インデックスの質は検索結果に直結します。
古い情報や関係ない文章が混ざると、AIが誤った回答を出す原因となります。
正確な出力のためには、必要な情報だけを残し、見出しや項目ごとに整理しておくことが重要です。
データのメンテナンスと更新
RAGの精度を保つには、データベースの定期的な更新が欠かせません。
古い情報を残したままだと、検索結果や回答の信頼性が下がります。
常に最新の情報を反映するために、新しいデータの追加と不要なデータの削除が必要です。
自動更新の仕組みを導入すれば、パフォーマンスの維持にも効果的です。
RAGの実装プロセス
ImageFXで作成
RAGを実装する方法は、利用環境や要件に応じて異なります。
主に、ChatGPTを活用した構築、クラウド環境での構築、ローカル環境での構築の3つのアプローチがあります。
それぞれの方法にはメリットと適用範囲が異なるため、ここからは各実装方法について詳しく解説します。
ChatGPTを活用したRAG構築
ChatGPTと外部データベースを組み合わせることで、高精度なテキスト生成と最新情報の提供が可能です。
手軽にRAGを実装できる点が魅力です。
OpenAIのAPIを使えば、RAGの検索機能を補完する形で活用でき、大規模なモデルの再学習も不要。
導入コストを抑えられます。
ただし、API利用に伴うコストや、機密情報の取り扱いには注意が必要です。
クラウド環境でのRAG構築
RAGを構築するなら、AWSやGCPなどのクラウド環境が最適です。
クラウド環境では、処理量に応じて性能を柔軟に拡張できるスケーラブルな設計が可能です。
ElasticsearchやFAISSによる検索機能の実装も容易で、リソースの自動スケールや最適化にも対応できます。
BigQueryやAWS Lambdaを使えば、効率的なデータ処理も実現可能。
ただし、運用コストを抑えるためには使用状況に応じたリソース管理が必要です。
ローカル環境でのRAG構築
セキュリティ重視やクラウド依存を避けたい企業には、ローカル環境でのRAG構築が適しています。
高いカスタマイズ性とデータ保護が強みです。
自社内のデータベースや検索エンジン(FAISSやElasticsearch)を使って、独自のRAGシステムを構築可能です。
ただし、大規模なデータ処理には高性能なハードウェアが必要となり、運用や保守の負担が増える点には注意が必要です。
まとめ

ImageFXで作成
RAG(検索拡張生成)は、生成AIの精度を向上させ、リアルタイムで正確な情報提供を可能にする技術です。
従来の生成AIは、特定時点までのデータしか学習していないため、新しい情報が反映されない「知識のカットオフ問題」が発生します。
また、事実とは異なる内容を生成する「ハルシネーション(幻覚・虚偽回答)」のリスクもあります。
これらの課題を解決するために、RAGを導入する方法には、以下の3つの選択肢があります:
- ChatGPTを活用したRAG構築: 既存の生成モデルと組み合わせる手軽な方法
- クラウド環境でのRAG構築: AWSやGCPを活用し、大規模データに対応
- ローカル環境でのRAG構築: セキュリティを強化し、独自データを活用
自社のニーズに合った方法を選び、RAGを活用して業務の効率化や情報検索の最適化を進めましょう。