セマンティック検索とは?仕組み・全文検索との違い・実装方法まで徹底解説
セマンティック検索は、ユーザーの検索意図や文脈を理解し、最適な検索結果を提供する技術です。
従来のキーワードマッチングに依存する検索とは異なり、入力されたクエリの意味を解析し、関連性の高い情報を抽出します。この技術により、ユーザーはより的確な情報を迅速に得ることが可能となります。
本記事では、このセマンティック検索の基本から仕組み、活用事例、実装方法までをわかりやすく解説します。
また、弊社ではマッキンゼーやGAFA出身のAIエキスパートがAI導入に関する無料相談を承っております。
無料相談は先着20社様限定で「貴社のAI活用余地分析レポート」を無償でご提供するキャンペーンも実施中です。
ご興味をお持ちの方は、以下のリンクよりご連絡ください:
AI導入に関する無料相談はこちら
資料請求はこちら

セマンティック検索とは?

セマンティック検索とは、検索エンジンがユーザーの検索クエリの背後にある意味や意図を理解し、それに基づいて関連性の高い結果を提供する技術です。
従来のキーワードベースの検索では、入力された単語と完全一致または部分一致する文書が主に表示されていました。しかし、セマンティック検索では、自然言語処理(NLP)や機械学習を活用し、ユーザーの意図や文脈を解析することで、より適切な情報を提供します。
例えば、「ジョブズの発明品」と検索すると、セマンティック検索は「スティーブ・ジョブズが発明した製品」を意味すると理解し、「Mac」や「iPhone」などの関連する結果を表示します。
セマンティック検索の仕組み

セマンティック検索は、自然言語処理(NLP)、ベクトル検索、コンテキスト理解の3つの要素により、検索エンジンはユーザーのクエリの意味を深く把握し、より適切な検索結果を提示することが可能になります。
ここでは、それぞれの技術がどのように機能し、セマンティック検索に貢献しているのかを詳しく解説していきます。
自然言語処理(NLP)
自然言語処理(NLP)は、人間の言語をコンピュータが理解・解析・生成する技術です。
セマンティック検索では、NLPを用いてユーザーの検索クエリを解析し、文法構造や意味を理解します。これで同義語や関連語、さらには文脈を考慮した検索が可能となります。
例えば、「スマートフォンの進化」と「携帯電話の発展」というクエリは異なる表現ですが、NLPを活用することで、これらが類似の意図を持つと判断し、関連する検索結果を得ることができるようになりました。
ベクトル検索
ベクトル検索とは、文章の意味を「数字のまとまり」に変換し、その数字同士の距離を使って似ているかどうかを判断する方法です。
セマンティック検索では、検索キーワードと文書の内容をそれぞれ数値に変換し、その数値の向きや角度を比べることで、どれだけ似ているかを調べて判断する仕組みです。※これをコサイン類似度(同じ方向を向いている=意味が近い)と呼びます。
つまり、たとえ使っている言葉が違っていても、意味が近ければ関連性の高い結果を表示することが可能です。
例えば「AI技術の応用例」と検索すると、「人工知能を活用した事例紹介」という文章も、意味が似ていると判断されて検索結果に出てくる可能性があります。
コンテキスト理解
コンテキスト理解とは、ユーザーの検索クエリが置かれた状況や背景を考慮し、適切な検索結果を提供する技術です。これには、ユーザーの過去の検索履歴・位置情報・デバイス情報などが活用されます。
例えば、同じ「カフェ」という検索クエリでも、ユーザーが朝に検索した場合と夜に検索した場合で、表示される結果が異なることがあります。朝であればモーニングメニューを提供するカフェが、夜であればバータイムを提供するカフェが優先的に表示されるといった具合です。
セマンティック検索と全文検索の違い

セマンティック検索と全文検索は、情報検索の手法として広く用いられていますが、そのアプローチや適用範囲には明確な違いがあります。
ここでは、その違いを詳しく見ていきます。
【前提】全文検索とは
全文検索とは、文書内のすべてのテキストを対象に、指定されたキーワードやフレーズを検索する手法です。
主に、文書内の単語の出現頻度や位置情報を基に、検索結果をランキングします。
例えば、「データ分析」というキーワードで全文検索を行うと、そのキーワードが含まれる文書がヒットします。しかし、関連する「ビッグデータ解析」や「データマイニング」といった同義語や関連語が含まれる文書は、キーワードが一致しないため、検索結果に表示されない場合があるかもしれません。
用途の違い
全文検索は、特定のキーワードやフレーズが含まれる文書を迅速に見つける際に有効です。
一方、セマンティック検索は、ユーザーの検索意図や文脈を理解し、関連性の高い情報を提供することを目的としています。
例えば、ユーザーが「最新のスマホ」と検索した場合、セマンティック検索は「最新のスマートフォン」に関する情報を提供します。しかし、全文検索では「最新」と「スマホ」というキーワードが含まれる文書のみを表示するため、関連性の高い結果もキーワードが含まれなければ表示されまれません。
検索手法の違い
全文検索は、キーワードの文字列一致に基づく検索手法であり、主にインデックスを活用して高速な検索を表示します。
対照的にセマンティック検索は、自然言語処理や機械学習を活用して、テキストの意味や文脈を理解しながら検索を行います。
全文検索では、検索クエリと一致する単語やフレーズの有無が主なマッチング条件となり、単語の表記ゆれや言い換えに弱い傾向があります。
一方でセマンティック検索は、文章を数値ベクトルに変換して意味的な類似度を評価するため、キーワードが異なっていても関連性の高い情報を見つけることができます。
例えば、「パソコンの電源が入らない」という検索に対して、セマンティック検索では「PCが起動しない」「ノートPCが反応しない」といった異なる表現のFAQや記事を表示可能です。これにより、ユーザーが使う言葉に依存せず、求める情報へスムーズにたどり着けるという利点があります。
セマンティック検索のメリット

セマンティック検索には、従来のキーワードベース検索と比べてさまざまな利点があります。ユーザーの検索意図に沿った精度の高い検索結果が得られることに加え、多言語対応のしやすさや柔軟な情報マッチングといった点が挙げられます。
以下では、主な3つのメリットについて詳しく解説します。
キーワードに依存しない柔軟なマッチング
セマンティック検索は、検索クエリと完全に一致するキーワードが含まれていなくても、意味的に関連する情報を探し出せる点が最大の強みです。これは、ベクトル化された文書同士の意味的な距離を測ることで、近い概念を持つ文書を抽出できるためです。
例えば、「電車に乗って通勤する方法」と検索した際に、「公共交通機関を使った通勤術」といった、直接キーワードが含まれない記事でも、関連性が高いと判断して表示することができます。
このような柔軟なマッチングは、特に語彙が異なるユーザー間で共通の情報ニーズに対応する際に有効です。
文脈や意図を反映した精度の向上
セマンティック検索は、単語単位ではなくクエリ全体の意味や意図を理解するため、検索結果の精度が大幅に向上します。自然言語処理により、曖昧な表現や文脈を適切に解釈することで、ユーザーが求める本質的な情報により近いコンテンツを提示します。
たとえば「スマホ 充電できない」と検索した場合、単なる充電器の紹介記事ではなく、「スマートフォンが充電できないときの対処法」といった実用的な情報が上位に表示されやすくなります。
このように、単語そのものではなく「ユーザーが何を知りたいのか」という視点で結果が返されることが、セマンティック検索の大きな利点です。
マルチリンガル対応のしやすさ
セマンティック検索は、言語に依存しない検索技術であり、多言語環境にも柔軟に対応できます。ベクトル空間に変換されたテキストは、異なる言語間でも意味的な類似性を評価できるため、多言語にまたがる情報検索が容易になります。
たとえば、日本語で「環境にやさしい車」と検索しても、英語で「eco-friendly cars」と記載された文書が高いスコアで返されることがあります。
この特性は、グローバルな情報発信や多言語対応が求められるWebサービス、あるいは社内のナレッジ検索などにおいて非常に効果的です。
セマンティック検索の具体的な活用事例

セマンティック検索は、企業や公共機関のナレッジ共有やFAQシステム、顧客サポートなど多様な領域で活用されています。
ここでは、実際に導入している日本企業の事例として、「住友電工情報システム」と「中国電力株式会社」による取り組みを紹介します。
それぞれの活用シーンを通じて、セマンティック検索がどのような課題解決に貢献しているのかを見ていきましょう。
住友電工情報システム
住友電工情報システムでは、膨大な社内技術文書やナレッジから必要な情報を効率的に探し出すことが難しいという課題を抱えていました。この問題を解決するため、同社は自社開発のセマンティック検索エンジン「QuickSolution」を導入しています。
従来のキーワード検索では、表現の違いや文脈を考慮できず、目的の情報にたどり着くまで多くの時間を要していました。そこで自然言語処理を活用した検索機能を開発し、表現の揺らぎや文脈を踏まえた柔軟な情報抽出を可能にしています。
その結果、検索作業の効率が向上しただけでなく、社内ナレッジの再活用も進みました。技術者間の知識共有も円滑になり、QuickSolutionは今や他社展開も進む注目の製品となっています。
中国電力株式会社
中国電力株式会社は、社内に分散する複数システム間での横断検索や、権限管理を維持した高速な検索処理に課題を抱えていました。
これを解決するため、同社は住友電工情報システムのセマンティック検索エンジン「QuickSolution」を導入しました。その結果、さまざまなファイル形式に対応した一括検索や、平均5秒の応答速度を実現しています。
導入後は検索工数が大幅に削減され、FAQの検索対象拡大や社内ポータルとの連携によって利便性も向上しました。さらに社内クラウド活用により構築コストを約半分に抑えるなど、全体的なシステム最適化が進んでいます。
現在は生成AIとの連携で、検索結果を活用した質問応答機能の実装も視野に入れています。
セマンティック検索のPythonによる実装方法

セマンティック検索はPythonを用いることで、比較的手軽に自社システムへ組み込むことが可能です。
特に、自然言語処理に特化したライブラリやフレームワークが豊富に揃っているため、要件に応じた柔軟な実装が実現できます。
ここでは代表的な2つの実装方法として、①Sentence Transformersを用いた実装、②Haystackフレームワークを利用した実装手順を解説します。
1️⃣Sentence Transformersを使用した実装
Sentence Transformersは、文や文書のベクトル表現を高精度で生成できるライブラリです。
検索エンジンの一種である「Elasticsearch(エラスティックサーチ)」と組み合わせることで、意味に基づいた高度な検索システムを作ることができます。(Elasticsearchは、大量のデータをすばやく検索・分析できるオープンソースのツールです。)
以下のステップで、Elasticsearchと連携させたセマンティック検索システムを構築できます。
✳️ステップ1:Machine Learningの有効化
セマンティック検索を行うには、Elasticsearchで「機械学習(Machine Learning/ML)」機能が有効になっている必要があります。この機能が無効のままだと、検索モデルのインポートや推論処理が実行できません。
Elasticsearchを自前のサーバーなどで運用している場合(オンプレミス環境)は、以下のように設定ファイルを編集します。

設定後、Elasticsearchを再起動すればML機能が有効になります。
Elastic Cloudを利用している場合は、通常、機械学習機能は最初から有効です。
✳️ステップ2:Eland Python Clientのインストール
Elasticsearchに自然言語処理モデルを取り込むには、「Eland(イーランド)」というPythonクライアントが必要です。
このツールを使うと、Hugging Faceなどから取得したTransformerモデルを、Elasticsearchにインポートできる形式に変換できます。まずは、Python環境で以下のコマンドを実行してElandをインストールしましょう。

インストールが完了したら、「eland_import_hub_model」コマンドなどが使えるようになります。次のステップでは、このコマンドを使って学習済みモデルを取り込んでいきます。
✳️ステップ3:学習済みモデルのインポート
次に、セマンティック検索に使う「学習済みモデル」をElasticsearchにインポートします。
ここでは、Hugging Face で公開されている Sentence Transformers モデルを使用し、「eland_import_hub_model」コマンドでElasticsearch用に変換します。
以下は、モデル「all-MiniLM-L6-v2」をインポートする例です。
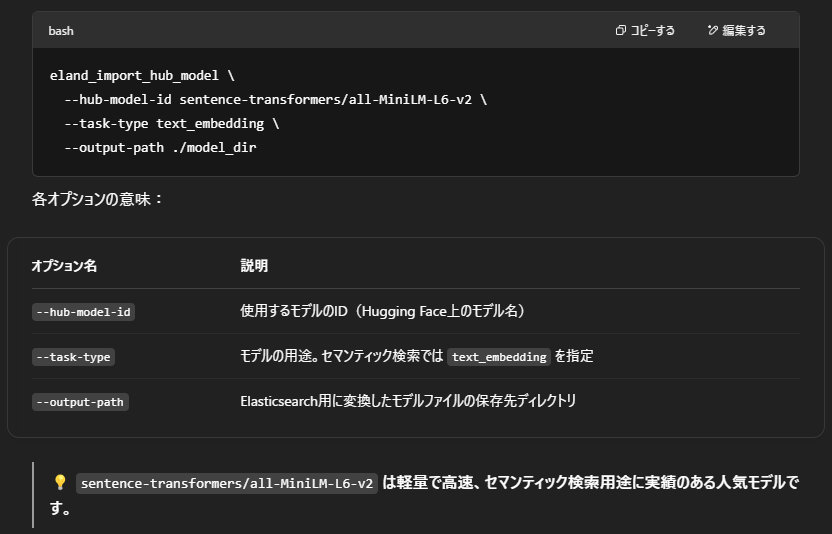
インポートが成功すると、指定したフォルダ(./model_dir)にElasticsearch形式のモデルデータが出力されます。このファイルを次のステップでKibanaからデプロイして使います。
※注意:transformersパッケージも必要になることがあります。以下で事前インストールを推奨:pip install transformers
✳️ステップ4:KibanaでのモデルデプロイとIngest Pipelineの設定
前ステップでインポートした学習済みモデルを、Elasticsearch上で使えるようにするためには、「デプロイ(起動)」と「Ingest Pipeline(取り込み処理)」の設定が必要です。
この作業は、Kibana という管理ツールを使います。
🧩モデルのデプロイ(Kibana上)
Kibanaにアクセスし、以下の順で操作します:
- 左側のメニューから「Stack Management > Machine Learning > Model Management」を開く
- インポート済みモデルが一覧に表示されていることを確認
- 対象モデルの右端メニューから「Start Deployment(デプロイを開始)」をクリック
これで、Elasticsearch内でそのモデルが検索に使える状態になります。
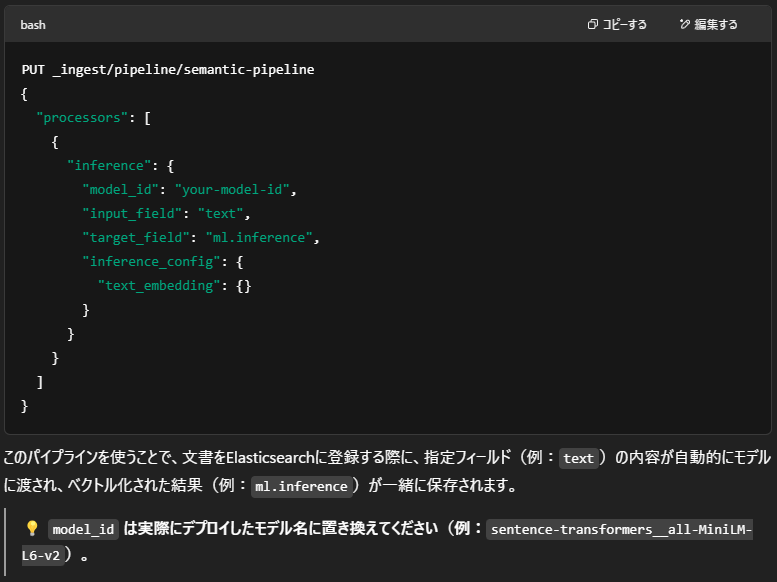
🧩Ingest Pipeline の作成(API操作例)
次に、文書を登録する際に自動でベクトル変換を行うよう、Ingest Pipeline を設定します。
以下はその一例です:
🧩最後に:インデックス作成例
このパイプラインを使って文書を登録するには、次のようにインデックス指定と一緒に pipline を明記します:
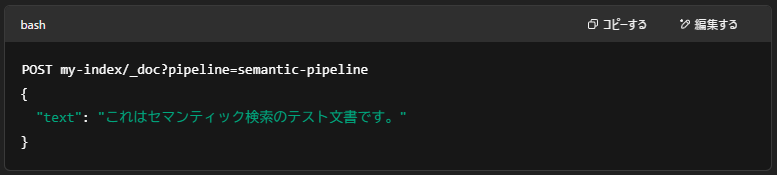
これで登録と同時にベクトルが生成され、セマンティック検索に使える状態になります。
2️⃣Haystackフレームワークを使用した実装
Haystackは、質問応答やセマンティック検索、ドキュメント検索のためのPython製フレームワークです。
ElasticSearch・OpenSearch・FAISSなどさまざまなバックエンドに対応し、簡単に検索パイプラインを構築できます。
✳️ステップ1:Haystackのインストール
まずは必要なパッケージをインストールします。Haystackには多くの依存ライブラリがあるため、[all] オプションで一括インストールするのが便利です。
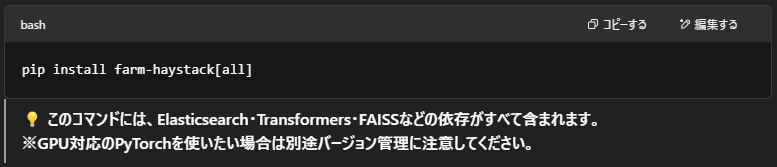
✳️ステップ2:RetrieverとReaderの初期化
Haystackでは、検索パイプラインの基本構成として「Retriever(候補文書の取得)」と「Reader(文書の読み取りと回答抽出)」の2つを用意します。
これで、高速かつ精度の高いセマンティック検索が可能になります。
🧩Retrieverの初期化(Elasticsearchを使う例)
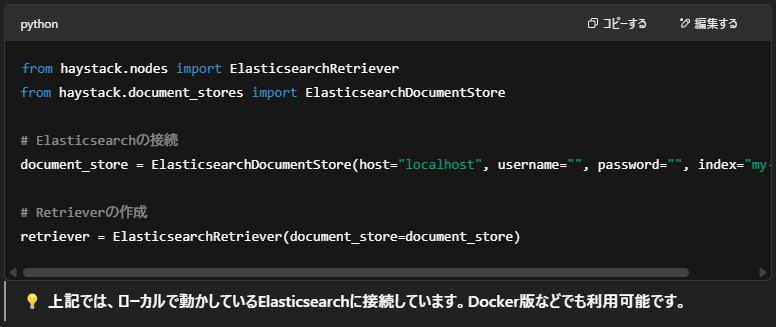
🧩Readerの初期化(Transformerモデルを使う)
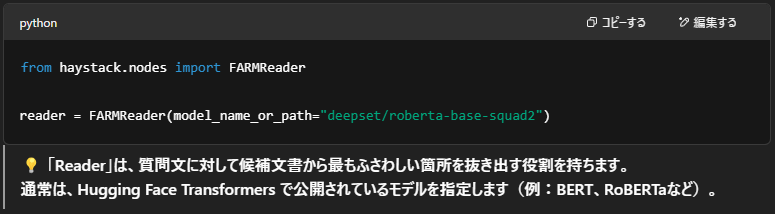
✔️Retriever と Reader を使う理由
- Retriever:全文データから意味的に関連のある文書を高速で抽出(ベクトル検索など)
- Reader:抽出された文書から、より正確に答えの候補を見つけ出す
この2段構えにより、キーワード一致では拾えない「意図に近い答え」が得られるのがHaystackの強みです。
✳️ステップ3:検索パイプラインの構築
RetrieverとReaderを準備したら、それらをつなぎ合わせて検索パイプライン(検索フロー)を構築します。
これにより、「質問 → 文書検索 → 回答抽出」という一連の処理を1ステップで実行できます。
🧩パイプラインの作成
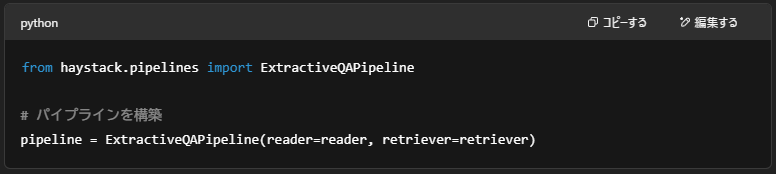
🧩質問に対して検索を実行
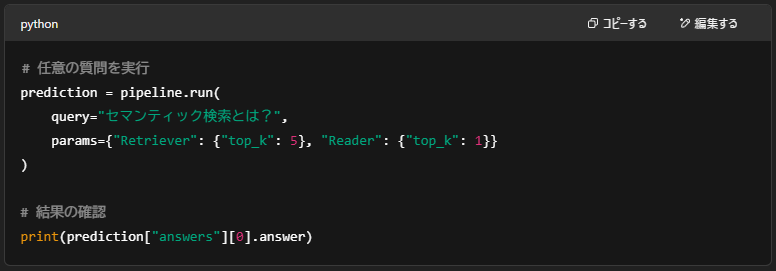
🔍オプションの説明
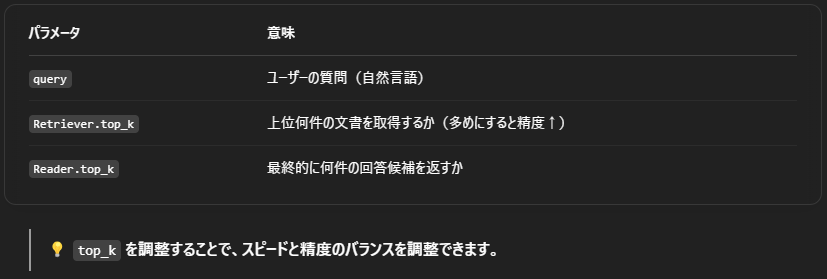
このパイプラインにより、ユーザーが質問文を投げると候補文書の中から意味的に関連し、かつ最も適切な回答が抽出される仕組みになります。
✳️ステップ4:アプリケーションの実行
パイプラインが完成したら、実際にそれをユーザーが使える検索アプリケーションとして動かせるようにします。
Haystackでは、APIサーバーとして公開したり、Webアプリケーションと統合することも簡単です。
🧩最も手軽な方法:FastAPIでAPI化
Haystackには、APIを立ち上げるための便利な機能が組み込まれています。
以下は最小構成の例です:
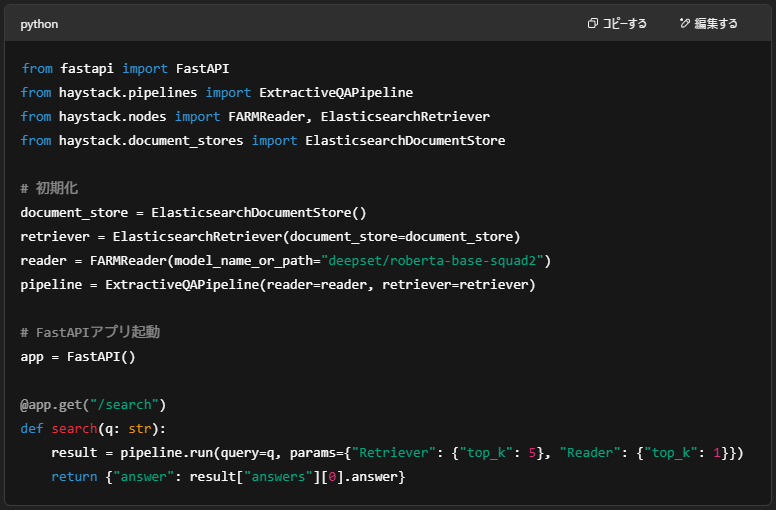
これを保存し、以下のように実行します:

すると、http://localhost:8000/search?q=セマンティック検索とは? のようなURLにアクセスすれば、APIとして回答を取得できます。
💡 その他の実行方法
- Streamlit や Gradio を使えばGUI付きのWebアプリとして簡単に表示可能
- Flask などの軽量フレームワークでカスタマイズ性重視のWeb化も可能
- Haystack公式の UIテンプレート も活用可能
まとめ

セマンティック検索は、検索クエリの「意味」や「意図」を理解し、より関連性の高い情報を返す次世代型の検索技術です。
従来のキーワードマッチングでは対応しきれなかった文脈理解や表現のゆらぎ、多言語対応といった課題を克服し検索精度とユーザー体験の大幅な向上を実現します。
住友電工情報システムや中国電力といった実際の活用事例からも分かるように、ナレッジマネジメントやカスタマーサポートなど幅広い業務領域での導入が進んでいます。
さらに、Pythonと自然言語処理ライブラリ(Sentence TransformersやHaystackなど)を活用すれば、企業内でも自社に適したセマンティック検索基盤を比較的手軽に構築可能です。
今後も生成AIや多言語翻訳との統合が進むことで、セマンティック検索はより進化し情報探索のあり方を根本から変えていくでしょう。

