Stable Diffusion WebUI完全ガイド|Forge版・インストール・使い方・拡張機能まで徹底解説
Stable Diffusion WebUIを使ってみたいけど、インストール方法やForge版との違いがよくわからず困っている方も多いのではないでしょうか?
Stable Diffusionはオープンソースで自由にカスタマイズ可能な点から、クリエイターや技術者を中心に高い人気を誇っている中で、「WebUIとは何か」「Forge版やReForge版のどちらを選ぶべきか」といった疑問を持つ方は多いかと思います。
この記事では、Stable Diffusion WebUIの基礎知識からインストールや拡張機能の活用法、アップデート時の注意点まで丁寧に解説していきますので、Stable Diffusion WebUIについて基本から体系的に理解し、安心して導入したい方は、是非最後までご覧ください。
また、弊社ではマッキンゼーやGAFA出身のAIエキスパートがAI導入に関する無料相談を承っております。
無料相談は先着20社様限定で「貴社のAI活用余地分析レポート」を無償でご提供するキャンペーンも実施中です。
ご興味をお持ちの方は、以下のリンクよりご連絡ください:
AI導入に関する無料相談はこちら
資料請求はこちら

AI導入.comを提供するビルドAI株式会社 代表取締役。トロント大学コンピューターサイエンス学科卒業。株式会社ANIFTYを創業後、世界初のブロックチェーンサービスを開発し、東証プライム上場企業に売却。その後、マッキンゼー・アンド・カンパニーにコンサルタントとして入社。マッキンゼー日本オフィス初の生成AIプロジェクトに従事後、ビルドAI株式会社を創業。

Stable Diffusion WebUIとは?
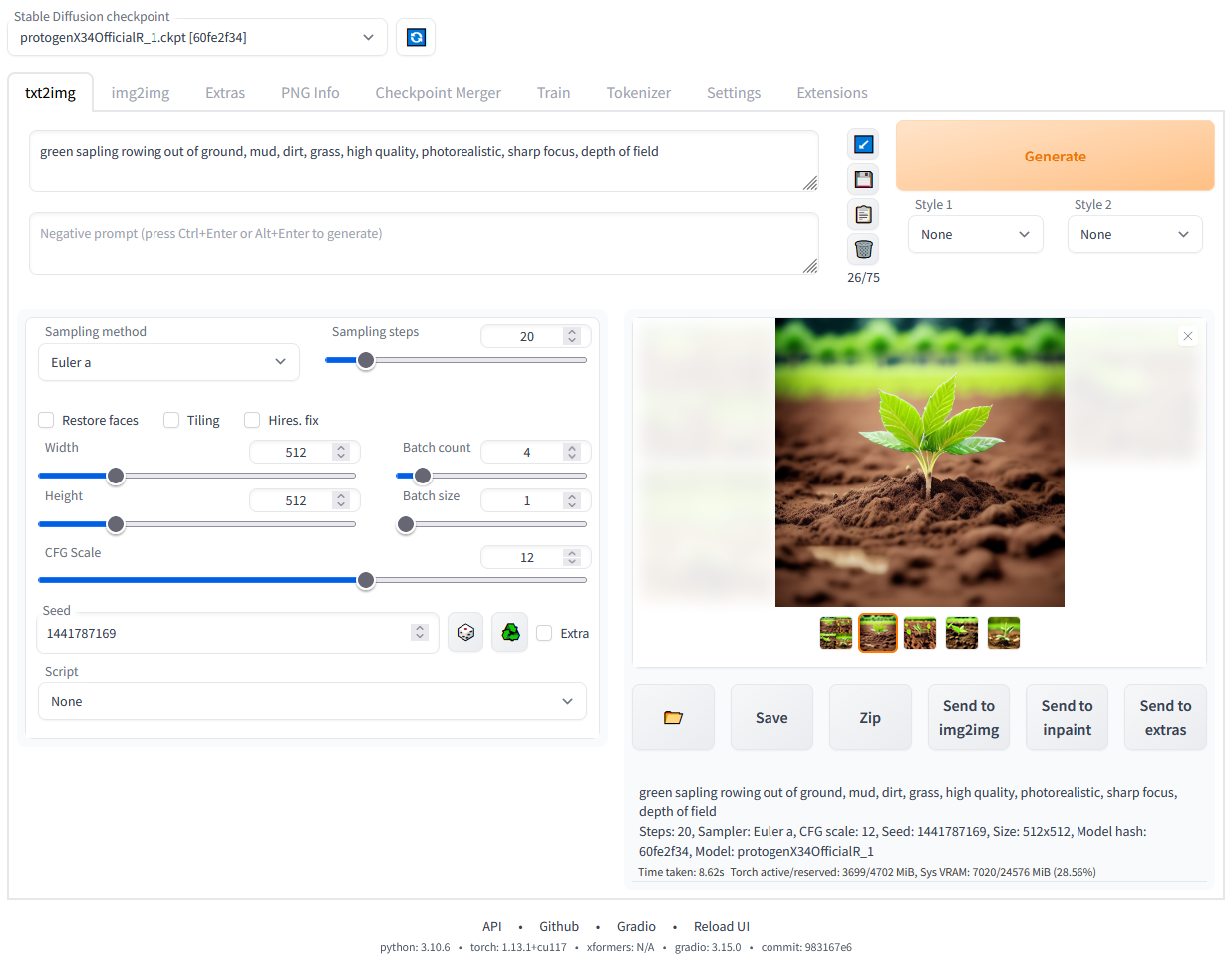
Stable Diffusion WebUIとは、Stable DiffusionモデルをGUI経由で操作できるブラウザベースのユーザーインターフェースです。
GradioというWebアプリフレームワーク上に構築されており、プログラミング不要でテキストや画像からAIによる画像生成を行えます。
特にAutomatic1111氏による実装版は最も広く利用されているWebUIで、豊富な機能と拡張性によりユーザーが様々な設定を試しながら簡便に画像生成を行うことができます。
Stable Diffusion WebUI Forge版とReForge版の違い
Stable Diffusion WebUIにはさまざまな派生版があり、その中でも特にForge版とReForge版の違いがよく分からないという方も多いのではないでしょうか。
以降では、これらの派生版の具体的な違いを比較し、どのようなケースでどちらを選べば良いかを詳しく説明します。

Forge版とReForge版の比較
Stable Diffusion WebUIには有志による改良版として、Forge版とreForge版があります。
どちらもAutomatic1111版WebUIをベースに開発された派生プロジェクトで、開発効率の向上やリソース管理の最適化、推論速度の高速化などを目的としています。
Forge版はControlNetの開発者として知られるlllyasviel氏(Lvmin Zhang氏)によって開始され、低VRAM環境でも画像生成が可能な高度なメモリ最適化や追加のサンプラー実装など、オリジナル版にない実験的機能を多数導入した点が特徴です。
一方、reForge版はForge版の開発が大幅な仕様変更(Gradio 4.xへの移行など)を伴う実験的ブランチに移行したことを受け、従来のForge版(Gradio 3.x環境)をベースに互換性を維持しつつ改良を継続する後継プロジェクトとしてコミュニティ主導で開発されています。
両者ともAutomatic1111版より動作が軽量で、例えばreForge版ではわずかVRAM 2GBのGPUでもStable Diffusionを動作可能と報告されています。
Forge版を選ぶべきケース
Forge版本家(lllyasviel氏によるプロジェクト)の最新版は、Gradio 4.x対応など最先端の実験的機能を取り込んだブランチとして開発されており、一部の高度なユーザー以外には非推奨とされています。
そのため、最新技術の検証やFluxと呼ばれる新しい拡張モデルへの対応など、拡張性・実験性を重視してリスクを許容できる上級者がForge版を選ぶべきケースと言えます。
つまり、最新の機能をいち早く試したい、あるいはForge版でしか利用できない独自機能(例:FLUXモデル対応)が必要な場合に限り、Forge版を検討すると良いでしょう。
ただしこの場合、従来の拡張機能が動作しない可能性や不安定さも念頭に置く必要があります。
ReForge版を選ぶべきケース
一般的なユーザーや安定性重視の用途であれば、reForge版の利用が適しています。
reForge版は従来のStable Diffusion WebUI拡張エコシステムとの高い互換性を保ちながらForge版由来の高速・省メモリ動作を引き継いでおり、通常のStable Diffusion 1.5やSDXLによる画像生成を快適に行えます。
2025年現在、開発もコミュニティによって継続的に行われており、Auto1111の拡張機能の約80%が使用できる高い互換性を誇ります。オリジナル版WebUIの更新や既存拡張機能との両立も考慮されているため、拡張機能を多用する場合や安定した環境で使いたい場合はreForge版が推奨されます。
特にPCのVRAMが少ない場合でも動作報告があり(VRAM 2GB程度でも動作可能)、手持ちのハードウェアで無理なく動かせる利点に加え、--cuda-malloc、--cuda-stream、--pin-shared-memoryなどの最適化フラグによる高速化も可能です。
Stable Diffusion WebUIのインストール方法
ここからは、Stable Diffusion WebUIをWindows、Mac、Linuxなどの環境で導入する方法を丁寧に解説します。
初めての方でも安心してセットアップできるよう詳しく説明していますので、ぜひ参考にしてください。

必要ソフトウェアの準備(Python・Git)
Stable Diffusion WebUIをローカル環境で動かすには、事前にPythonとGitという2つのソフトウェアをインストールしておく必要があります。
PythonはStable Diffusionの実行に必要なプログラミング言語環境で、バージョンは3.10.6の64bit版が推奨されています。2025年現在でも、ライブラリの互換性とPyTorchサポートの関係上、Python 3.10.6を使用するのが最も安定しています。
Gitはプログラムのソースコードを取得・更新するためのツールで、WebUI本体のダウンロードやアップデートに使用します。インストール前にこれらがシステムに用意されているか確認しましょう。
PythonとGitのインストール
お使いのOSに合わせてPythonとGitをインストールします。
Windowsの場合、Python公式サイトからPython 3.10.6のインストーラを入手して実行し、「Add Python to PATH(環境変数に追加)」にチェックを入れてインストールしてください。
Gitも同様にGit公式サイトからインストーラをダウンロードしてインストールします。
macOSやLinuxの場合、システムにPython3やGitが標準で含まれていることも多いですが、含まれていない場合はHomebrewやaptといったパッケージ管理システムを利用してpython3およびgitをインストールできます。
例えばUbuntuではターミナルで以下のように実行して環境を整備します:
sudo apt install git python3.10 python3.10-venv -y
WebUIのダウンロード
必要ソフトの準備ができたら、Stable Diffusion WebUI本体のコードをダウンロード(クローン)します。
Gitを使うことで最新版のWebUIを取得できます。
まずインストール先とする任意のフォルダでターミナル/コマンドプロンプトを開き、以下のコマンドを実行します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
上記によりstable-diffusion-webuiというフォルダにプログラム一式がダウンロードされます(※Forge版やreForge版を使いたい場合はそれぞれのGitHubリポジトリURLを指定してクローンします)。
ダウンロード後、必要に応じてStable Diffusionの学習済みモデル(例:v1-5-pruned.ckptやsdxl_base_1.0.safetensorsなど)を入手し、WebUIフォルダ内のmodels/Stable-diffusionディレクトリに配置してください。
WebUIの起動
WebUI本体を取得したら、いよいよサーバーを起動します。Windowsの場合は、ダウンロードしたフォルダ内にあるwebui-user.batファイルをダブルクリックするだけでOKです。初回起動時には必要なPythonライブラリやモデルの自動ダウンロードが行われるため、完了までしばらく待ちます。
macOS/Linuxの場合は、ターミナルでWebUIフォルダに移動し、シェルスクリプトwebui.shを実行します(例:./webui.sh)。
初回実行時にはPyTorch等の環境セットアップが自動的に行われます。
起動プロセスの最後で「Running on local URL: http://127.0.0.1:7860」と表示されたら成功です。Webブラウザでそのアドレスにアクセスすると、Stable Diffusion WebUIの画面が表示されます。
起動エラーの対処方法
起動時にエラーが発生する場合は、落ち着いて原因を確認しましょう。
Windowsで起動直後にウィンドウが閉じてしまう場合、エラーメッセージが見えないため、対処としてwebui-user.batを右クリックして「編集」を選び、末尾にpauseと追記して再度実行するとエラー内容を確認できます(もしくはコマンドプロンプトからwebui-user.batを実行するとそのまま表示が残ります)。
よくある原因としてはPythonのバージョンの不適合があります。
例えばWindows環境で推奨と異なる古いPythonを使っていると、xformers関連のエラー(“NameError: name 'xformers' is not defined”など)が出ることがありますが、これはPythonを3.10にすることで解決します。
また“NVIDIAのCUDAが見つからない/対応していない”といったエラーが出る場合は、GPUドライバやインストールされたPyTorchがGPU非対応になっている可能性があります。
その場合は最新のグラフィックドライバを導入するか、再インストール時に対応するオプション(例:--use-cpuやAMDの場合の--no-half)を指定してみてください。
何らかの理由で起動に失敗する場合でも、大抵はエラーメッセージにヒントが書かれているので、メッセージ内容をもとに公式WikiのトラブルシューティングやコミュニティのQ&Aを調べると解決策が見つかります。
Stable Diffusion WebUIの基本操作方法
Stable Diffusion WebUIの基本操作方法は、テキストから画像を生成する方法(txt2img)や画像をもとに画像を生成する方法(img2img)の大きく2種類があります。
ここからは、それぞれの操作方法を見ていきましょう。

テキストから画像を生成する方法(txt2img)
txt2imgタブでは、テキストによる指示を与えて画像を生成できます。
まずWebUIを開き、上部メニューから「txt2img」タブを選択します。
画面中央のテキストボックスに、生成したい画像の内容をできるだけ詳細に説明するプロンプト(文章)を入力します。
例えば「夕焼けの海岸に立つ塔」や「幻想的な森の中に佇む城」のように、欲しい画像を言語で表現します。
必要に応じてパラメータも設定しましょう。
主なパラメータには、画像生成の反復回数を決めるSampling Steps(サンプリングステップ数)、生成時の画像の解像度(WidthとHeight)、画像の細部生成に影響を与えるCFG Scale(プロンプトへの従順さの度合い)などがあります。
パラメータを調整したら、画面下部の「Generate(生成)」ボタンをクリックします。
すると指定したAIモデルを用いて拡散モデルの推論が実行され、入力したテキスト内容に沿った画像が生成されます。
生成が完了するとWebUI上に画像のプレビューが表示され、自動的にファイルとしても保存されます(保存場所は後述)。
画像をもとに画像を生成する方法(img2img)
img2imgタブでは、既存の画像を入力として、それを元にしたバリエーション画像や加工画像を生成できます。
操作手順はtxt2imgと似ていますが、追加で入力画像を指定する点が異なります。
まず「img2img」タブに切り替え、中央の画像アップロード欄にベースにしたい元画像をドラッグ&ドロップするか、クリックしてファイル選択からアップロードします。
次に、その画像に対してどのような変化を加えたいかをテキストプロンプトで指定します。
例えば元画像が線画であれば「色彩豊かに塗り絵したイラスト」にしたい、といった具合に指示を文章で入力します。
また、img2img特有の重要なパラメータとしてDenoising strength(ノイズ除去強度)があります。
これは元画像のどの程度を維持するかを指定する値で、0に近いほど入力画像に忠実な出力となり、1.0に近づくほど元画像から離れて自由に生成されます。
この値を調整し、他のSampling StepsやCFG Scale等のパラメータも必要に応じて設定したら、Generateボタンを押して生成を開始します。
AIは入力した元画像を下地としつつプロンプトの指示に沿って画像を変換し、新しい画像を出力します。
例えばラフなスケッチを入力して詳細なアート風画像に変換したり、写真をもとに絵画調にレンダリングし直す、といった多彩な応用が可能です。
生成した画像を保存する方法
Stable Diffusion WebUIで生成された画像は、自動的にファイル保存される仕組みになっています。
デフォルトではWebUIのフォルダ内にあるoutputsディレクトリに、実行したタブ名(txt2imgまたはimg2img)ごとのサブフォルダが作成され、その中に日時を含むファイル名で画像が保存されます。
たとえばtxt2imgで生成した画像はoutputs/txt2img-images/フォルダにPNG形式で出力されます。
ファイル名には日時やシード値などが含まれるため後から識別しやすく、またPNG画像のメタデータにプロンプトやパラメータが記録されているので、後で同じ設定を再現することも可能です。
生成直後にWebUI上でプレビュー表示された画像についても、各画像の下に操作ボタンが表示されます。
フロッピーディスクアイコンの「Save」ボタンを押せば、その画像データを手動でダウンロード保存することもできます。
また「PNG Info」タブに画像をドラッグ&ドロップすれば、埋め込まれたプロンプト等の情報を確認できます。
必要に応じてこうした機能も活用してください。
Stable Diffusion WebUIの拡張機能の使い方
ここからは、Stable Diffusion WebUIの拡張機能について、代表的な導入方法や、ControlNet・LoRAといった主要な拡張機能を活用する手順を詳しく紹介します。
WebUIの機能をさらに活用したい方は参考にしてください。

拡張機能を導入する方法
Stable Diffusion WebUIはプラグイン方式の拡張機能(Extensions)を追加することで機能を拡張できます。
新たな拡張機能を導入するには、WebUI画面上部の「Extensions」タブを開きます。
まず「Available」タブで公式拡張の一覧を更新・表示できますが、任意の拡張を追加するには「Install from URL」欄を使う方法が簡単です。
そこにインストールしたい拡張機能のGitリポジトリURL(GitHub上のURL)を貼り付け、「Install」ボタンをクリックします。
例えばControlNet拡張を追加したい場合、https://github.com/Mikubill/sd-webui-controlnetというURLを入力してInstallを押すことで、自動的に必要なファイルがextensionsフォルダにクローンされます。
インストールが完了したら、画面上部の「Apply and restart UI」ボタンをクリックしてWebUIを再起動してください。
再起動後に拡張機能が有効化され、その拡張独自の機能がUI上に反映されます。
なお、直接extensionsディレクトリにGit cloneすることで手動導入することも可能ですが、内蔵のインストール機能を使う方が簡便です。
代表的な拡張機能の使い方(ControlNet・LoRAなど)
代表的な拡張機能としてControlNetとLoRAについて紹介します。
ControlNetの使用方法:
ControlNetは画像生成時に追加の条件(姿勢や輪郭など)を与えることで結果を制御できる強力な拡張機能です。
例えば人物のポーズを指定したり、下絵の線画に沿って着色させたりといった用途が可能です。
ControlNet拡張を導入すると、txt2imgやimg2imgタブ内にControlNet用のパネルが表示されます。
まずこのパネルで使用したいControlNetモデル(例えばOpenPose=姿勢検出やCanny=輪郭検出など)を選択し、対応する参照用画像をアップロードします。
次に通常通りテキストプロンプトを入力し、必要であればControlNetパネル内の各種設定(推論の重みや前処理フィルタ等)を調整してから生成を実行します。
するとAIはテキストプロンプトに加えて参照画像から抽出された情報(例えばポーズの骨格や輪郭線)も条件(コンディショニング)として考慮し、より思い通りの構図・形状で画像を生成できます。
ControlNetを使うことで、単なるテキスト指示だけでは得られない細かな構図指定が可能となり、創作の幅が大きく広がります。
LoRAの使用方法:
LoRA(Low-Rank Adaptation)はStable Diffusionの学習済みモデルに対して特定の絵柄やキャラクターの特徴を後付けできる軽量な追加モデルです。
拡張機能というより追加のモデルファイルですが、WebUIで簡単に利用できます。
LoRAモデル(拡張子が.ptや.safetensorsのファイル)を入手したら、WebUIのmodels/Loraフォルダにそのファイルを配置してください。
配置後はWebUIを再起動することでLoRAが読み込まれ、生成時に使用可能になります。
LoRAを適用するには、プロンプト中に特殊なタグを書く方法が一般的です。
書式は <lora:LoRA名:重み> となっており、例えばモデル名が"exampleStyle"のLoRAを強度0.8で使いたい場合、プロンプト文の適切な場所に <lora:exampleStyle:0.8> と記述します。
Automatic1111版WebUIやその派生版(Forge、ReForge)ではプロンプト中にこの表記を含めるだけで対応するLoRAが自動的に適用され、画像生成に反映されます。
適用後は、そのLoRAに固有の画風やキャラクター性が画像に反映されます。
なお、ReForge版では内蔵のLoRA管理機能が向上しており、UI上でチェックボックスやスライダーによってLoRAを管理・調整することも可能です。しかし、基本的な使用法は上述の通りプロンプトへのタグ追加だけで十分です。
Stable Diffusion WebUIをアップデートする方法
ここからは、WebUIを最新の状態に保つためのアップデート手順や注意点を初心者にも分かりやすく説明します。
安全に更新を行いたい方はぜひご確認ください。

アップデート手順
Stable Diffusion WebUI本体を最新版にアップデートするには、インストール時に取得したGitリポジトリから最新のコミットを取り込むのが一般的です。
具体的には、WebUIをインストールしたフォルダでターミナル(コマンドプロンプト)を開き、次のコマンドを実行します。
git pull
これにより、リポジトリに加えられた最新の変更点がローカル環境に反映されます。
Gitでクローンしてインストールしていれば、この手順で常に最新バージョンへ更新できます。
更新が完了したら、再度WebUIの起動スクリプト(webui-user.batまたはwebui.sh)を実行しましょう。
必要に応じて依存ライブラリのアップデートも自動で行われ、最新のWebUIが起動します。
なお、Windows向けの一括インストーラ等を利用した場合は、同梱のupdate.batを実行することで同様に最新化が可能です。
アップデート時の注意点
アップデートを行う際にはいくつかの注意点があります。
まず、WebUI本体を更新した後は導入済み拡張機能の互換性に注意しましょう。
WebUI本体の更新に伴い、一部の拡張が古いままだと不具合が起きる場合があります。
そのため、アップデート後には「Extensions」タブで**“Check for updates”(更新確認)ボタンを押して、インストール済み拡張機能のアップデートがあるか確認してください。
更新がある拡張についてはチェックボックスを入れて適用し、UIを再起動することで拡張機能側も最新版に合わせておくと安心です。
次に、アップデート前に設定のバックアップを取っておくことも推奨されます。
設定ファイル(例えばconfig.jsonやwebui-user.sh内のオプションなど)やカスタムスクリプトを手動で変更している場合、アップデート作業で上書きされたり動作が変化する可能性があるためです。
また、大きなアップデート後に不具合が発生した場合に備え、以前のバージョンのブランチやコミットに戻す方法(Gitのrollbackや以前のリリースタグをチェックアウトする等)も把握しておくと良いでしょう。
基本的には慎重に手順を踏めば問題なく更新できますが、アップデート後に問題が生じた際は公式の変更ログやコミュニティの情報を確認し、必要に応じて対処してください。
まとめ

本記事では、Stable Diffusion WebUIの基本知識からインストール方法、派生版の選び方、操作方法、拡張機能の活用法、アップデート手順まで幅広く解説してきました。
これらのポイントを押さえておくことで、Stable Diffusion WebUIをより効果的に利用できるようになります。
ぜひ実際の活用にお役立てください。