【完全版】Stable Diffusionの公式&おすすめ派生モデル25選
高品質な画像をテキスト入力から生成できるオープンソースAIモデル「Stable Diffusion」。公式モデルは日々進化し、派生モデルも次々登場しています。その中で、どのモデルが自分の画像生成に適しているか迷っている方も多いのではないでしょうか。
本記事では、Stable Diffusionのおすすめモデルを公式モデルからコミュニティ派生モデルまで、最新情報を交えて網羅的にご紹介します。
Stable Diffusion(ステイブルディフュージョン)の進化の歴史、多様なモデルの特徴、最適な導入・活用方法について知りたい方は、ぜひ最後までご覧ください。
また、弊社ではマッキンゼーやGAFA出身のAIエキスパートがAI導入に関する無料相談を承っております。
無料相談は先着20社様限定で「貴社のAI活用余地分析レポート」を無償でご提供するキャンペーンも実施中です。
ご興味をお持ちの方は、以下のリンクよりご連絡ください:
AI導入に関する無料相談はこちら
資料請求はこちら

AI導入.comを提供するビルドAI株式会社 代表取締役。トロント大学コンピューターサイエンス学科卒業。株式会社ANIFTYを創業後、世界初のブロックチェーンサービスを開発し、東証プライム上場企業に売却。その後、マッキンゼー・アンド・カンパニーにコンサルタントとして入社。マッキンゼー日本オフィス初の生成AIプロジェクトに従事後、ビルドAI株式会社を創業。

Stable Diffusionとは?

Stable Diffusionは、深層学習の拡散モデル(Diffusion Model)をベースとした画像生成AIです。
2022年に初期バージョンが公開されました。それ以降、次々と派生モデルが登場しています。アニメ・イラストやリアル写真風、芸術的表現などに特化したモデルが日々新たにアップロードされています。
本記事ではStable Diffusionの多様なモデルの選び方を解説し、おすすめモデルを紹介します。Stable Diffusionの基本的な使い方について知りたい方は、以下の記事をご覧ください。

Stable Diffusionベースの画像生成AIモデルの数は?

Stable Diffusionをベースとした画像生成AIモデルの開発は非常に活発です。現在、数百から数千のモデルが開発されていると言われています。
Hugging FaceやCivitaiといった画像生成AIの共有プラットホームには、多くのStable Diffusion派生モデルが掲載されています。
モデル数が非常に多いため、選定は難しい作業です。効果的に活用するには、目的に適したモデルを見極める能力が重要になります。
画像生成AIモデルを選ぶ時の5つのポイント

画像生成AIを選ぶ際には、どのような観点でモデルを評価すべきかを理解することが重要です。
具体的なモデル紹介の前に、画像生成AIモデルを選ぶ際の5つの重要な観点を紹介します。
パラメータ数
モデルのパラメータ数は、生成画像の品質や詳細度に直結します。パラメータ数が多いモデルほど、複雑な特徴や微細なテクスチャを表現できます。
ただし、パラメータ数が多いモデルは、処理に高い計算資源が必要になる点に注意が必要です。
解像度
モデルが扱える最大解像度は、生成画像の鮮明さや細部の表現力に大きく影響します。高解像度対応モデルほど、クリアでリアルな画像を生成できます。
用途やデバイスに合わせた適切な解像度のモデルを選ぶことが重要です。
ベースモデル(学習済みモデルの場合)
学習済みモデルを選ぶ際は、どの公式モデルをベースにチューニングされているかを確認しましょう。
良質なベースモデルを使用している画像生成AIは、多様なスタイルに対応し、カスタマイズも容易です。これにより、生成画質や将来的なメンテナンス品質も確保されやすくなります。
計算リソース要件
画像生成AIを利用する際は、必要な計算リソースを確認することが重要です。
モデルによって必要なGPU/TPUのタイプやメモリ容量が異なります。リソース要件によって運用コストや使いやすさが大きく変わるため、自分の環境に合ったモデルを選びましょう。
コミュニティとサポート体制
モデルを提供するプラットフォームやコミュニティのサポート体制も重要な選定基準です。
充実したドキュメントや活発なコミュニティがあれば、問題解決や活用方法の習得がスムーズになります。
Stable Diffusionの公式モデル10種類

Stable Diffusionは公式から複数のモデルが公開されています。
以下の表では、Stable Diffusion公式モデルの主要バージョンとその特徴をまとめました。
| モデル名 | リリース時期 | パラメータ数 (概算) | 解像度 | 主な特徴 |
|---|---|---|---|---|
| Stable Diffusion 1.4 | 2022年8月 | 約9億 | 512×512 | 初期公開モデル。軽量かつ汎用性が高い。 |
| Stable Diffusion 1.5 | 2022年10月 | 約9億 | 512×512 | 1.4を改良し、出力の鮮明さ・安定性を向上。 |
| Stable Diffusion 2.0 | 2022年11月 | 約10億 | 768×768 | 新テキストエンコーダ採用、解像度拡張。アダルト画像フィルター強化。 |
| Stable Diffusion 2.1 | 2022年12月 | 約10億 | 768×768 | 2.0のマイナーアップデート。NSFWフィルタを緩和。 |
| Stable Diffusion XL | 2023年7月 | 約35億 | 1024×1024 | 解像度や手・文字の精度を大幅向上。GPU要件が高い。 |
| Stable Diffusion XL Turbo | 2023年11月 | 非公開 | 512×512 | SDXLの蒸留版。少ない拡散ステップで高速生成。 |
| Stable Diffusion 3.0 | 2024年2月(早期プレビュー) | 8億〜80億 | 1024×1024 | "Diffusion Transformer"採用。文字生成能力向上。 |
| Stable Diffusion 3.5 Large | 2024年10月 | 80億 | 1メガピクセル | 高品質・高適応性。プロフェッショナル用途向け。 |
| Stable Diffusion 3.5 Large Turbo | 2024年10月 | 非公開 | 1メガピクセル | 3.5 Largeの蒸留版。高速画像生成が可能。 |
| Stable Diffusion 3.5 Medium | 2024年10月 | 25億 | 0.25〜2メガピクセル | MMDiT-Xアーキテクチャ採用。一般消費者向けハードウェア対応。 |
Stable Diffusionのモデルは大きく4つの系統に分類できます:1系(1.4/1.5)、2系(2.0/2.1)、SDXL、SD3です。ここから各系統の特徴を簡単に紹介します。
1系(1.4/1.5)モデル
2022年の生成AI黎明期にリリースされたモデルです。軽量でローカル環境でも動作可能な点が特徴です。512x512pxの小サイズ画像生成に特化しています。
多くの拡張ツールやLoRAモデルが1系をベースに開発されており、エコシステムが充実しています。
2系(2.0/2.1)モデル
2022年末頃に発表された2系モデルは、解像度が768x768pxに向上し、よりリアルな描画表現が特徴です。
ただし、用途によっては1系と比べて再現性が低いケースもあり、ユーザーの好みが分かれるモデルとなっています。
XL系(SDXL、SDXL Turbo)モデル
2023年にリリースされたXL系は、パラメータ数の大幅増加と1024x1024pxへの解像度向上により、細部の再現度が大きく強化されています。
複雑な構図やリアルな質感表現に優れ、商用レベルの生成精度を実現しています。また、文章理解力が向上し、長文プロンプトにも対応できるため、使い勝手も大幅に改善されています。
3.0モデル
2024年にリリースされたSD3は、画像とテキストを同時に理解するマルチモーダル機能が特徴です。
生成品質が従来比で大幅に向上し、文字の描写や複数人物の自然な配置も得意としています。SDXLと同様に商用利用に適したスペックを持っています。
3.5系モデル(3.5 Large、3.5 Large Turboなど)
2024年末にリリースされた最新の3.5系モデルは、高いカスタマイズ性と効率的なパフォーマンスが特徴です。
3D、写真、絵画、線画など多彩なスタイルの画像を高品質で生成でき、現時点で最も商用利用に適しているモデルと評価されています。
Stable Diffusion派生モデルのおすすめ15選

ここからは、Stable Diffusionの公式モデルをベースに構築された派生モデルから、15の人気モデルをジャンル別に紹介します。これらのモデルは特定の画風や用途に特化しており、目的に合わせて選ぶことで生成結果の質が大きく向上します。
派生モデルのおすすめ【アニメ・イラスト風】
アニメ・イラスト風モデルは「鮮やかな輪郭と彩色」が特徴です。画像生成AIの中でも特に開発が盛んな領域となっています。
以下のモデルが特に人気を集めています。
| モデル名 | ベース | 特徴 | 備考 |
|---|---|---|---|
| Waifu Diffusion | SD1.4 | イラスト投稿サイトデータで追加学習。アニメ塗り再現 | 初期からのアニメ特化モデル |
| Anything | SD1.5 / SDXLベース | Danbooruタグ対応で詳細指定可能。V5ではSDXL統合 | 幅広いアニメ表現に対応 |
| Counterfeit | SD1.5 | 鮮やかな色彩とディテール重視のスタイル | 派手な背景やメカ描写も得意 |
| AbyssOrangeMix | マージモデル | 複数モデルのブレンドで鮮やかな発色を実現 | アニメ・ファンタジー系に強い |
| Kenshi | SD1.5 | キャラクターと衣装デザインの多様性に優れる | アバター作成によく使用される |
ここからはそれぞれのモデルの特徴を紹介します。
Waifu Diffusion

日本のアニメやラノベの挿絵風のモデルです。アニメ・美少女イラストに特化した細かい線画や塗りのスタイルを持っています。
目が大きく、髪の質感や服のディテールも丁寧で、二次元キャラの表現に優れています。NSFW(成人向け)にも対応可能です。
Anything
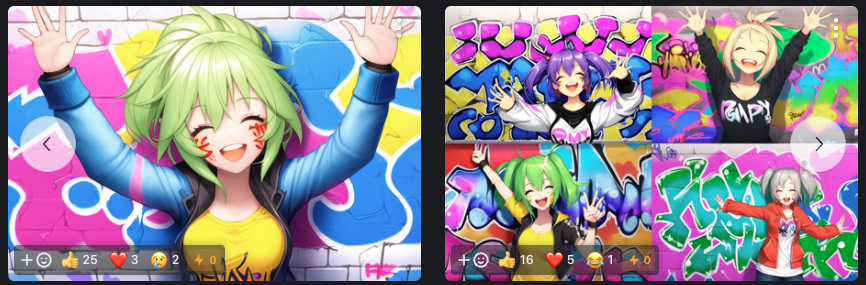
「Anything V3」「V4」などのバージョンがあり、Waifu Diffusionをベースにチューニングされた多用途アニメ系モデル。
ファンタジー・SF・現代系の背景まで幅広く生成できます。肌や目、髪の塗りにツヤ感が強め、かつキャラの表情やポーズの多様性も高いのが特徴で、自然な構図を得やすいモデルとなっています。
Counterfeit

アニメとリアルの中間的な画風。柔らかく繊細な陰影と線の少ない構成で、ちょっと幻想的な雰囲気が特徴です。
少女系キャラやポートレートに強く、ややデフォルメされた顔立ち。イラスト寄りながらも、彩度や照明効果を調整すれば実写風にも寄せられる万能型。
AbyssOrangeMix
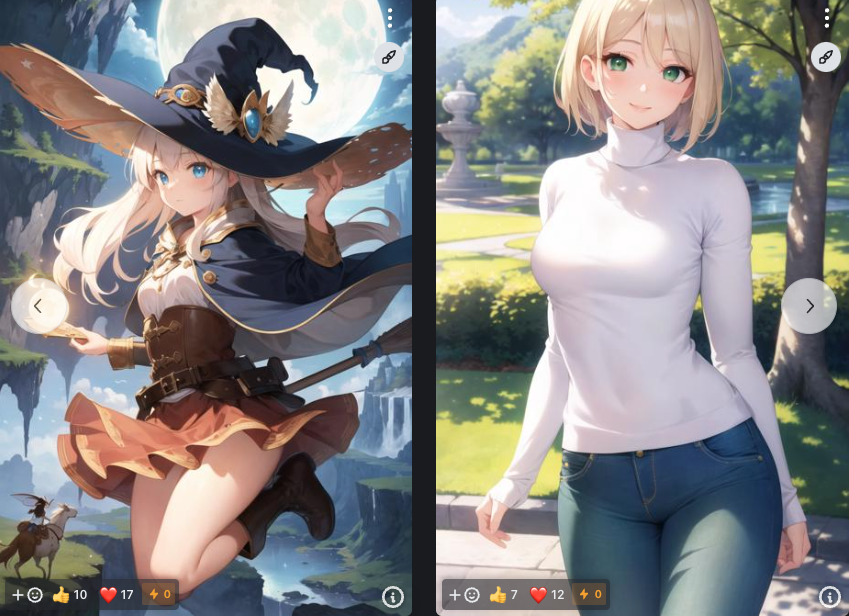
リアル寄りの美少女系に強い人気モデルです。色彩は鮮やかで、瞳や肌の描写が立体的なのが特徴です。
ファンタジー系や近未来的な背景との相性も良いモデルとなっています。
Kenshi
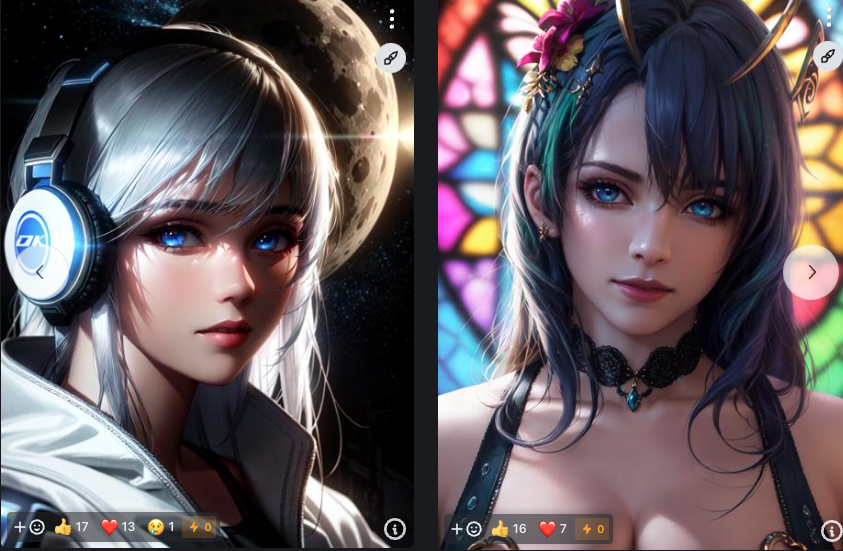
Kenshiは柔らかい塗りと繊細なライティングが特徴のアニメ風特化モデルです。
背景も自然に馴染み、全体として淡く温かみのある世界観を作ることが可能です。学園系や日常シーン、優しい雰囲気の作品に最適なモデルとなっています。
派生モデルのおすすめ【写真・リアル風】
写真・リアル風モデルは広告素材、商品撮影、コンセプトアートなど、実写に近い表現が求められる場面で活躍します。
以下に、写真風画像生成に特化した人気モデルを紹介します。
| モデル名 | ベース | 特徴 | 備考 |
|---|---|---|---|
| Realistic Vision | マージモデル | 肌質感・風景描写が高精細。広告・商品撮影風 | 人物から静物まで幅広く対応 |
| ChilloutMix | SD1.5 | アジア系ポートレートに特化。自然な表情表現 | 肌の質感や照明効果が高精度 |
| Analog Diffusion | SD1.5 | フィルムカメラ風のレトロな質感表現 | ノスタルジックな雰囲気表現に最適 |
| Deliberate | マージモデル | 写真とイラストの中間的表現が可能 | 初心者にも扱いやすく汎用性が高い |
| Juggernaut XL | SDXL | 高解像度・高精細な写実表現を追求 | 8GB以上VRAM推奨。商用利用向き |
ここからは各モデルの特徴を解説していきます。
Realistic Vision

写真のようなリアルな人物描写が得意な派生モデルです。
肌の質感、髪の流れ、ライティングが自然で、ポートレート生成が得意です。ファッションや日常風景とも相性が良く、モデル撮影のような仕上がりになるのが特徴です。
Chillout Mix
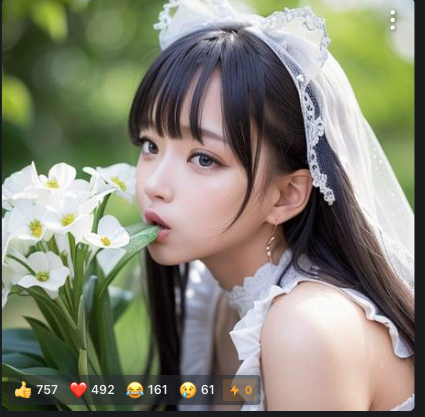
ChilloutMixは、アジア系のリアルな人物描写に強みを持つモデルです。肌や表情が柔らかく、自然な美しさが再現されます。
リアルとイラストの中間のような絵柄も得意で、日本人風のポートレートを生成したい方におすすめです。
Analog Diffusion

Analog Diffusionは、レトロなフィルムカメラ風の写真を再現できるモデルです。
粒子感のある質感や淡い色調が特徴で、ノスタルジックな雰囲気を表現したいときに最適です。昭和風の作風やアナログ感を求める方にぴったりです。
Deliberate

Deliberateは、リアルとイラストの中間を得意とする汎用性の高いモデルです。
柔らかな陰影や自然な表情が特徴で、ポートレートからファンタジー系の背景まで幅広い表現に対応できます。構図が破綻しにくく、初心者にも扱いやすい点も魅力です。
Juggernaut XL
高解像度かつリアリティ重視で設計されたモデルです。
顔の立体感や目の輝き、肌のディテールが非常に高精細で、商用レベルのクオリティを求める方に向いています。Stable Diffusion XLをベースにしており、構図の自由度も高いのが特長です。
派生モデルのおすすめ【特定スタイル特化型】
アニメやリアル系以外にも、特定の作品やスタイルに特化した多様な派生モデルが存在します。
以下に、特定のビジュアルスタイルを再現するための人気モデルを紹介します。
| モデル名 | ベースモデル | 特徴 | 用途 |
|---|---|---|---|
| Arcane Diffusion | Stable Diffusion 1.5 | Netflix『Arcane』の独特な美術スタイルを再現 | 同作品のファンアート制作に最適 |
| Ghibli Diffusion | Stable Diffusion 1.5 | ジブリ作品の温かみのある画風を再現 | 幻想的な風景や優しい雰囲気の作品に |
| NovelAIカスタムモデル | 独自モデル | 小説挿絵向けの高品質イラスト生成 | 物語のビジュアル化やキャラクター制作 |
| Pony Diffusion | Stable Diffusion XL | カートゥーン風の明るい色彩表現 | 『マイリトルポニー』風イラスト制作 |
| ANIMAGINE XL | Stable Diffusion XL | 高品質アニメ画像の生成に特化 | 手や細部の描写が重要なアニメイラスト |
以下に、各モデルのイメージと特徴を紹介します。
Arcane Diffusion
アニメ『Arcane』の独特なビジュアルスタイルを再現するモデルです。キャラクターの表情や背景の雰囲気など、作品特有のアートスタイルを忠実に再現できます。『Arcane』の世界観を取り入れたイラストやファンアートを作成したい場合に適しています。
Ghibli Diffusion

スタジオジブリ作品のような温かみのあるアニメーションスタイルを再現するモデルです。柔らかな色使いや幻想的な風景、優しい雰囲気のキャラクター描写が特徴で、ジブリ風のイラストやファンタジックなシーンの作成に適しています。
NovelAIカスタムモデル

小説や物語の挿絵に適した高品質なイラストを生成するモデルです。多彩なスタイルやテーマに対応し、ファンタジーから現代劇まで幅広いシーンを描写できます。物語のビジュアル化やオリジナルキャラクターのデザインに活用できます。
Pony Diffusion

『マイリトルポニー』のキャラクターやスタイルに特化したモデルです。カートゥーン風の明るい色彩とシンプルなデザインが特徴で、ポニーキャラクターのイラストやファンアートの作成に適しています。アニメ調の画像生成にも高い性能を発揮します。
ANIMAGINE XL

高品質なアニメ調画像を生成する最新のモデルです。プロンプトの理解度が高く、多彩なシーンやキャラクターを表現できます。手の描写や細部のディテールも向上しており、アニメ風のイラスト制作において高いクオリティを実現します。
Stable Diffusionのモデルを使う方法
ここでは、Stable Diffusionのモデルを実際に使うための具体的な手順を解説します。

モデルの入手と導入の流れ
Stable Diffusionモデルの導入は、「選択」→「ダウンロード」→「配置」→「読み込み」の4ステップで完了します。
1. モデルの選択とダウンロード
モデル配布サイト
以下の主要サイトからモデルを入手できます:
- Hugging Face: 公式モデルや高品質な派生モデルが豊富。詳細なドキュメントも充実
- Civitai: コミュニティ作成モデルの最大のハブ。サンプル画像やユーザーレビューが参考になる
ダウンロード手順
- 目的に合ったモデルのページにアクセス
- 「Download」または「Files」タブからモデルファイル(.ckpt/.safetensors形式)を選択
- ファイルサイズは通常1〜7GB程度。ダウンロードには時間がかかる場合があります
2. モデルの導入と使用
モデルファイルの配置
- Stable Diffusion Web UIをインストールしたフォルダ内の「models/Stable-diffusion」ディレクトリを開く
- ダウンロードしたモデルファイルをこのフォルダにコピーまたは移動
モデルの読み込みと使用
- Stable Diffusion Web UIを起動(通常は「webui-user.bat」または「webui.sh」を実行)
- インターフェース上部の「Stable Diffusion checkpoint」ドロップダウンメニューから導入したモデルを選択
- モデルが読み込まれると、そのモデルの特性を活かした画像生成が可能になります
Stable Diffusionの商用利用ガイド

Stable Diffusionで生成した画像を商用利用する際は、使用するモデルのライセンスを必ず確認する必要があります。モデルの種類によって商用利用の可否や条件が異なります。
公式モデルの商用利用条件
Stability AIが提供する公式モデル(SD1.4/1.5/2.0/2.1/SDXL/SD3など)は、CreativeML OpenRAIL++ライセンスのもとで提供されています。
商用利用可能な点:
- 生成画像の著作権はユーザーに帰属
- 商用・非商用を問わず利用可能
- クレジット表記は必須ではない
制限事項:
- 違法コンテンツの生成は禁止
- 有害コンテンツ(差別的表現など)の生成は禁止
- 他者の権利を侵害する使用は禁止
派生モデルの商用利用
コミュニティ開発の派生モデルは、独自のライセンス条件が設定されている場合があります。
確認すべきポイント:
- モデルページのライセンス情報を必ず確認
- 「Commercial Use」の表記(Civitaiなど)
- クレジット表記の要否
- 特定用途の制限(NFT禁止など)
商用利用を検討する場合は、Hugging FaceやCivitaiなどの配布サイトで各モデルのライセンス情報を詳細に確認してください。不明点がある場合はモデル作成者に直接問い合わせることをおすすめします。
最新の開発動向(2025年4月時点)
Stable Diffusionは急速に進化を続けており、最新情報を把握することで最適なモデル選択や活用が可能になります。
以下に、2025年3月末時点での注目すべき最新動向を紹介します。
Stable Virtual Camera:2D画像から3D動画へ
発表日: 2025年3月18日
Stability AIは、2D画像を没入型の3D動画に変換できる新技術「Stable Virtual Camera」の研究プレビュー版を公開しました。
この技術により、静止画から動的な3D表現が可能になり、VRコンテンツ制作やインタラクティブメディアなど、新たな表現領域が広がります。
映画業界のVFXの専門家がStability AIに参画
発表日: 2025年3月19日
『アバター』や『タイタニック』などの映画で数々のアカデミー賞を受賞したロバート・レガト氏がStability AIのチーフパイプラインアーキテクトに就任しました。
レガト氏の参画により、Stable Diffusionの技術が映画やテレビなどのプロフェッショナルな映像制作現場でより活用しやすくなると期待されています。特に高品質な映像制作ワークフローへの統合が進むでしょう。
まとめ:目的に合ったStable Diffusionモデルの選び方

Stable Diffusionの世界は非常に多様で、公式モデルだけでも1系、2系、SDXL、SD3と進化を続け、さらにコミュニティによって開発された数百種類以上の派生モデルが存在します。
用途別おすすめモデル
- アニメ・イラスト制作: Anything、Waifu Diffusion、AbyssOrangeMix
- 写真・リアル表現: Realistic Vision、ChilloutMix、Juggernaut XL
- 特定スタイル再現: Arcane Diffusion、Ghibli Diffusion
- 商用利用: SDXL、SD3.5系、Juggernaut XL(ライセンス確認必須)
- 低スペックPC向け: SD1.5系、Deliberate
効果的な活用のポイント
- 目的を明確に: 作りたい画像のスタイルや用途を明確にしてからモデル選択
- 複数モデルの併用: 用途に応じて複数のモデルを使い分ける
- 最新情報のチェック: CivitaiやHugging Face、公式Discordで最新モデル情報を入手
- プロンプトの最適化: 各モデルの特性に合わせたプロンプト調整で結果が大きく変わる
Stable Diffusionの技術は日進月歩で進化しています。この記事で紹介したモデルを参考に、あなたの創作活動に最適なモデルを見つけ、AI画像生成の可能性を広げてください。