【実践ガイド】Difyで始めるRAG構築の仕方を徹底解説
ここでは、オープンソースで提供されているLLMプラットフォームであるDifyを使いながら、RAG(Retrieval-Augmented Generation)を実装する方法を解説します。
具体的な手順や最適化のポイントを詳しく紹介し、社内文書検索やFAQボットなど幅広いユースケースに応用できるツールを解説します。
また、弊社ではマッキンゼーやGAFA出身のAIエキスパートがAI導入に関する無料相談を承っております。
無料相談は先着20社様限定で「貴社のAI活用余地分析レポート」を無償でご提供するキャンペーンも実施中です。
ご興味をお持ちの方は、以下のリンクよりご連絡ください:
AI導入に関する無料相談はこちら
資料請求はこちら

AI導入.comを提供するビルドAI株式会社 代表取締役。トロント大学コンピューターサイエンス学科卒業。株式会社ANIFTYを創業後、世界初のブロックチェーンサービスを開発し、東証プライム上場企業に売却。その後、マッキンゼー・アンド・カンパニーにコンサルタントとして入社。マッキンゼー日本オフィス初の生成AIプロジェクトに従事後、ビルドAI株式会社を創業。

Difyとは:ノーコードでAIアプリを構築できるプラットフォーム
Difyは、プログラミング不要でRAGシステムを含む高度なAIアプリケーションを構築できるオープンソースプラットフォームです。企業が抱える機密データの扱いやコスト面での課題を解決しながら、効率的にAI導入を進められます。
OpenAI GPT、Anthropic Claude、Google Geminiなど主要なLLMに対応し、APIキーの設定だけで利用できます。ドラッグ&ドロップ操作でワークフローを設計でき、プログラミング知識がなくても直感的にAIアプリケーションを作成できます。
RAGについてはナレッジ機能として実装されており、ベクトル検索やハイブリッド検索に対応し、多様な検索手法を選択できます。また、オープンソースソフトウェアのため、自社サーバーにセルフホスティングが可能で、機密データを外部に送信せずに運用できます。
Difyの機能や料金・活用事例は下記の記事にて詳しく解説しています。
是非ご覧ください。
RAGとは何か:基本概念とメリット
RAGは、外部の知識ベースを活用してLLMが回答を生成する手法です。従来のLLMでは学習データの範囲内でしか回答できませんが、RAGを使うことで最新情報や専門知識を含む回答を得ることができます。
RAGの仕組み
RAGシステムは以下の流れで動作します:
- ユーザーの質問をベクトル化してデータベースで検索
- 関連性の高い文書チャンクを取得
- 取得した情報をLLMに与えて回答を生成
- ユーザーに回答を返却
この仕組みにより、LLMが学習していない最新情報や専門知識にも対応できるようになります。
RAG導入のメリット
RAGを導入することで、以下のメリットが得られます:
- ハルシネーション(幻覚)の抑制:検索結果に基づく回答で正確性が向上
- 最新情報への対応:学習データの期限を超えた情報も活用可能
- 専門知識の活用:社内文書や業界特有の情報を反映した回答
- コストの削減:新しい学習を行わずに知識を拡張
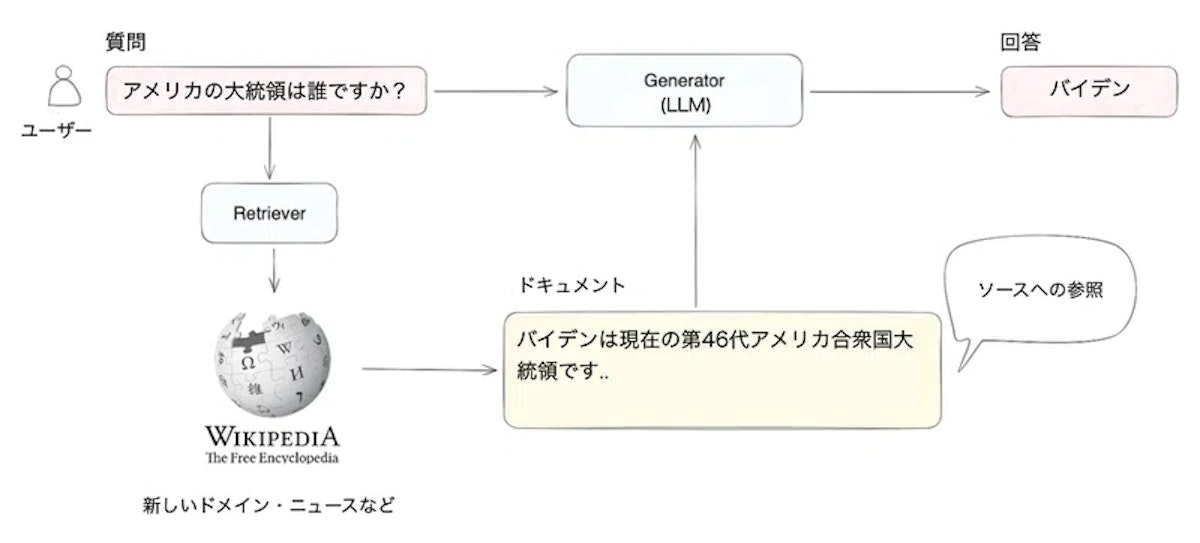
上記の図では、ユーザーが「アメリカ大統領は誰ですか?」と質問した際に、LLMが直接答えるのではなく、外部のベクトル化されたデータから最新情報を取得して回答している様子を示しています。
RAGの仕組み・実装方法・活用事例については以下の記事をご覧ください。
RAGの重要ポイント:検索精度と回答品質の向上

RAGシステムの成功は、検索精度と回答品質の両方を最適化することにかかっています。ここでは、DifyでRAGを実装する際に押さえておくべき重要なポイントを解説します。
RAGの構成要素
RAGシステムは以下の要素で構成されます:
ベクトルデータベース
文書をベクトル化して保存するデータベースです。ユーザーの質問もベクトル化し、類似度検索によって関連する文書を特定します。
Embeddingモデル
テキストをベクトル化するためのモデルです。日本語対応や専門分野への最適化など、用途に応じて適切なモデルを選択することが重要です。
Re-rankモデル
検索結果を再評価して順位を調整するモデルです。初期検索で取得した候補から、より関連性の高い文書を選別する役割を担います。
ハルシネーション抑制の仕組み
RAGでは、検索結果をプロンプトに含めることで、LLMが存在しない情報を生成するリスクを大幅に抑制できます。Difyのシステムプロンプト設定を活用すれば、「与えられた情報のみで回答する」といった制約を設けることで、さらに高い正確性を担保できます。
検索精度向上のアプローチ
効果的なRAGシステムを構築するには、以下のアプローチが重要です:
- 適切なチャンクサイズの設定:文書の意味的なまとまりを考慮した分割
- ハイブリッド検索の活用:ベクトル検索とキーワード検索の組み合わせ
- データの品質管理:重複や古い情報の定期的な整理
これらの要素を適切に設定することで、ユーザーの質問に対してより関連性の高い情報を提供できるRAGシステムが構築できます。
Difyでナレッジベースを作成する手順
DifyでRAGシステムを構築するには、まずナレッジベース(知識ベース)の作成から始めます。ここでは、具体的な作成手順を順番に解説します。
手順1:ナレッジの作成を開始
Difyの管理画面で「ナレッジの作成」を選択します。ナレッジベースは、RAGシステムの基盤となる重要な要素です。適切に設定することで、検索精度と回答品質の向上につながります。
手順2:データソースの選択
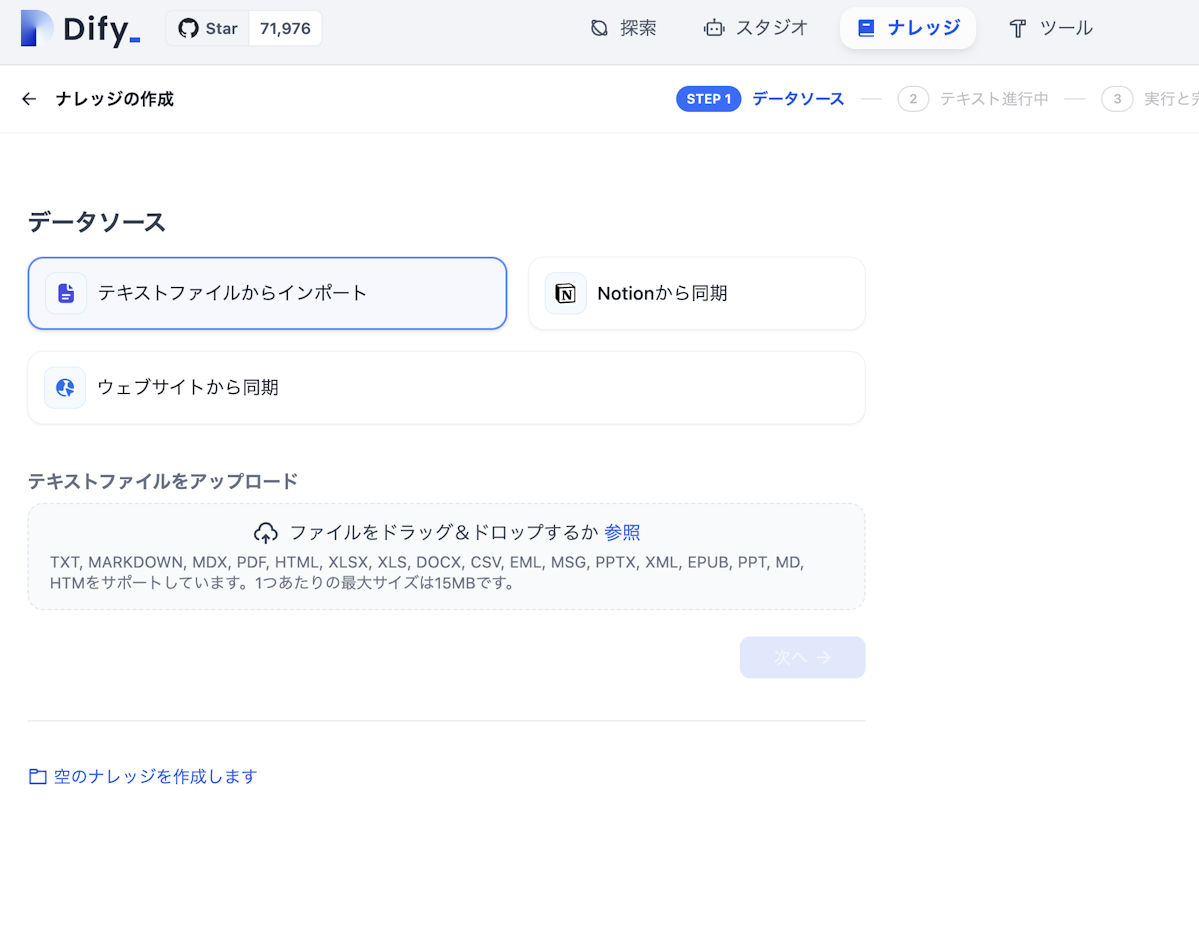
データソースとして以下の選択肢があります:
- PC上のファイル:PDF、Word、テキストファイルなど
- Notionのデータ:Notionページやデータベースの内容
- WEBサイトのデータ:公開されているウェブページの情報
企業の用途に応じて最適なデータソースを選択することが重要です。例えば、社内文書を活用する場合はPCファイル、ナレッジベースがNotionに構築されている場合はNotion連携を選択します。
手順3:チャンクと区切り文字の設定
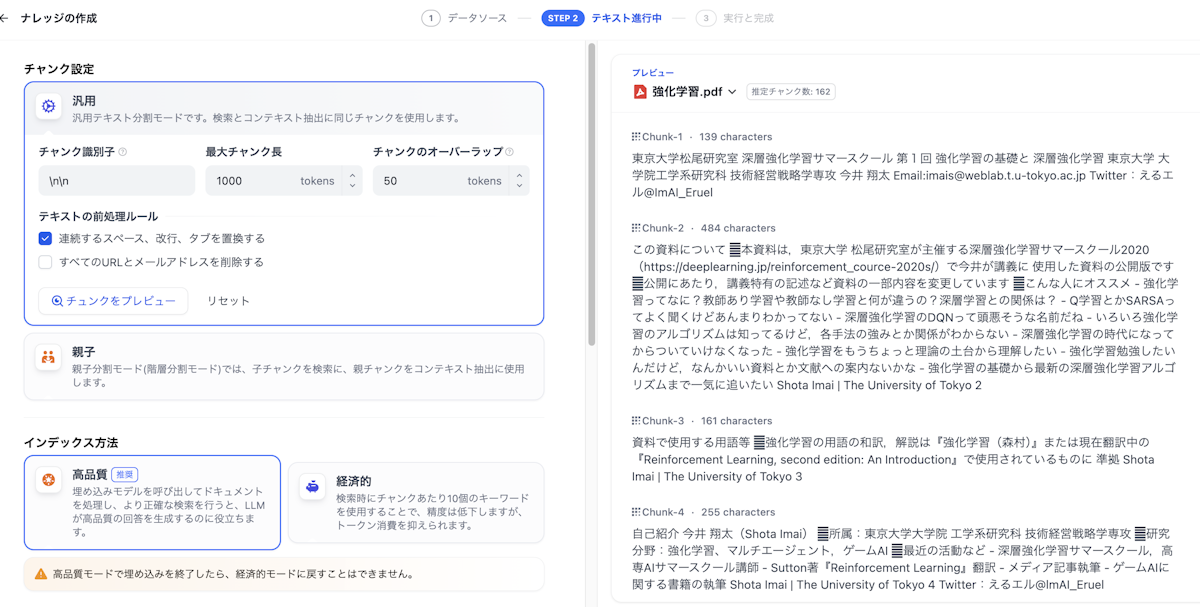
チャンクサイズと区切り文字の設定は、検索精度に大きく影響します。以下の点に注意して設定してください:
チャンクサイズの考慮点
- 意味的なまとまりごとに分割されるよう設定
- 文書の構造(見出し、段落)を考慮した区切り設定
- 検索時の関連性を高めるための適切なサイズ調整
事前準備の重要性
場合によっては、文書を事前に整理・修正することで、より効果的なチャンク分割が可能になります。見出し構造の明確化や不要な情報の削除などを検討してください。
手順4:インデックス方法の選択
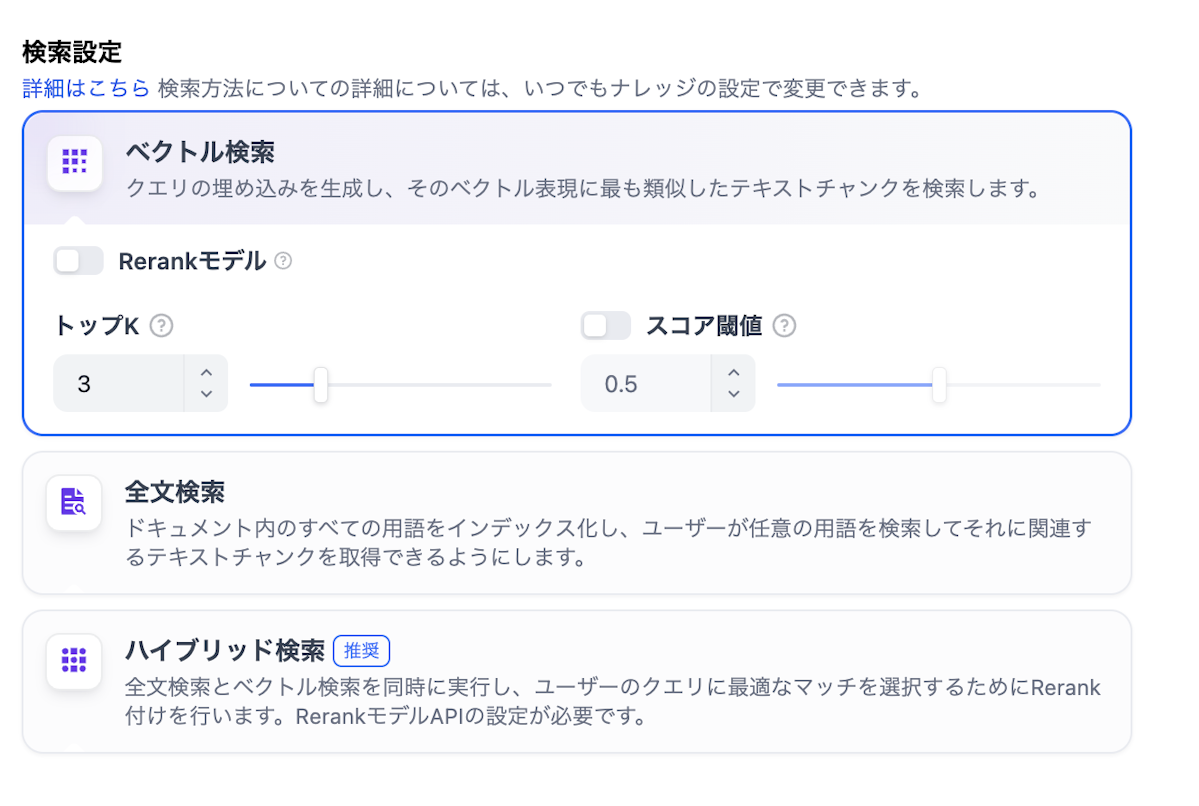
インデックス方法として以下のオプションが選択できます:
高品質(ベクトル検索)
意味的な類似性に基づく検索が可能です。専門用語や複雑な概念を含む文書に適しています。
経済的(キーワードのみ)
従来のキーワード検索のみを使用します。コストを抑えたい場合や、明確なキーワードで検索されることが多い場合に適しています。
ハイブリッド検索
ベクトル検索とキーワード検索を組み合わせ、両方の利点を活用できます。最も推奨される方法です。
Embeddingモデルの選択
CohereやOpenAIなどの高性能なEmbeddingモデルを設定することで、多言語対応や専門分野への最適化が可能になります。
手順5:検索テストで精度確認
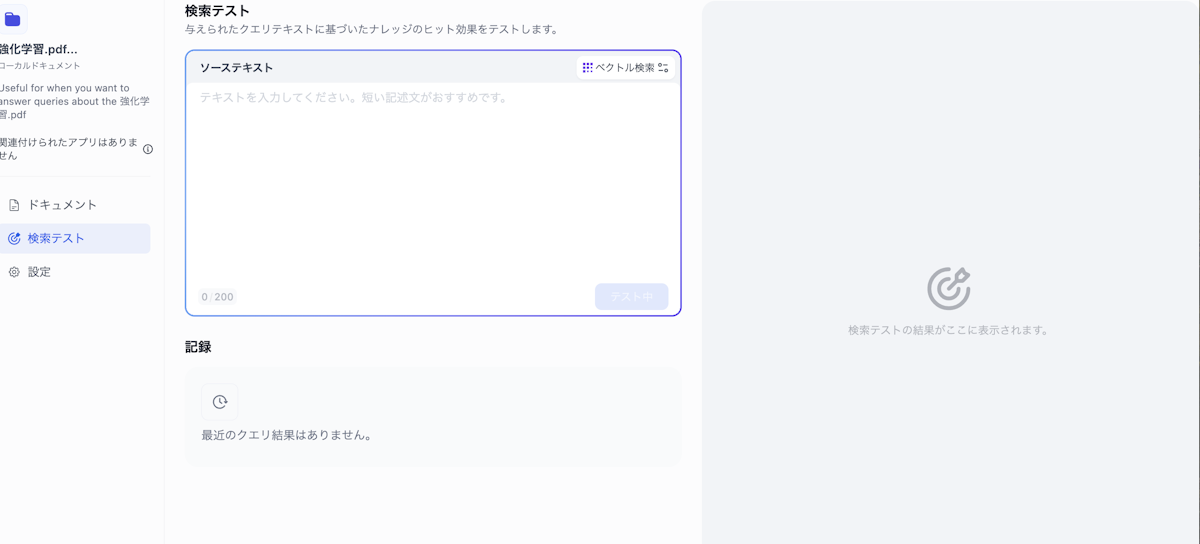
処理が完了したら、検索テスト機能を使って精度を確認します。実際の質問例を入力し、期待する文書が適切に検索されるかをチェックしてください。
精度が低い場合の対処法
- チャンク長の調整:短すぎる場合は長く、長すぎる場合は短く設定
- オーバーラップの修正:隣接するチャンク間の重複範囲を調整
- 区切り文字の見直し:文書構造により適した区切り方法を検討
継続的な調整と改善により、ユーザーのニーズに適したRAGシステムを構築できます。
Difyの今後の展望と最新動向

2025年2月にリリースされたDify v1.0.0では、プラグインシステムが正式導入され、AI開発プラットフォームとして新たな段階に入りました。120以上のプラグインを提供するDify Marketplaceが開設され、モデル、ツール、エージェント戦略、エクステンション、バンドルの5つのプラグインタイプが利用可能になっています。
プラグインエコシステムの構築
2025年の大きな変化として、Difyはモジュラーアーキテクチャへの転換を果たしました。従来はコアプラットフォームに統合されていたモデルやツールが、独立したプラグインとして動作するようになり、ホットスワップ対応によるリアルタイム拡張が可能です。
現在のマーケットプレイスには、OpenAI o1シリーズ、Gemini 2.0シリーズ、DeepSeek-R1などの最新モデルや、Perplexity、Discord、Slack、Firecrawlなどの多様なツールプラグインが提供されています。
エンタープライズ版の充実
コミュニティ版で240万ダウンロードを記録し、多数のフォーチュン500企業がエンタープライズ版を採用する中、Difyは企業向け機能を大幅に強化しています。プラグインシステムによるセキュアな環境での運用、ローカルデプロイメントによる機密データ保護、チーム内でのプラグイン共有機能などが充実しています。
AI技術の進歩への対応
2025年のAI技術の進歩に合わせ、Difyは以下の4つの核となる機能の強化を進めています:
- 推論能力の向上:強化学習ベースのLLMとの統合強化
- 実行能力の拡張:デジタル・物理環境での操作実行
- 動的メモリ機能:最適化されたRAGとメモリメカニズム
- マルチモーダルI/O:テキスト、画像、動画、音声の統合処理
パートナーエコシステムの拡大
v1.0.0のリリースパートナーとして、OpenRouter、Brave、E2B、SiliconFlow、Agora、Fish Audio、Dupdubなどとの連携を開始し、よりコンプリートで成熟したソリューションの提供を目指しています。
エージェントノードの導入により、ワークフローとチャットフローでインテリジェントなオーケストレーションが可能になり、ReAct、Function Calling、Chain-of-Thoughts、Tree-of-Thoughtsなどの推論戦略をプラグイン化して利用できます。
今後はデータ処理コンポーネントを活用したRAGワークフローの改善、業界特化型ユースケースの推進、グローバル開発者コミュニティとの協働を通じて、オープンで持続可能なエコシステムの構築を進めていく予定です。
まとめ:DifyでRAGを始める次のステップ
DifyによるRAG構築は、ノーコードに近い手順で高度なAIシステムを実現できる画期的なアプローチです。外部知識を融合した正確な回答システムを、プログラミング知識なしで構築できることは、多くの企業にとって大きなメリットとなります。
Dify RAGの主要な利点
DifyでRAGを構築することで得られる利点をまとめると:
- ノーコード開発:プログラミング不要で高度なAIシステムを構築
- 豊富な連携機能:複数のEmbeddingモデルやベクトルDBに対応
- セキュアな運用:オンプレミス導入により機密データを安全に活用
- 継続的な改善:検索テスト機能により精度の継続的な向上が可能
導入に向けた推奨ステップ
DifyでRAGシステムを導入する際は、以下のステップで進めることを推奨します:
1. 環境選択の検討
クラウド版とオンプレミス版のどちらが自社のセキュリティ要件に適しているかを検討してください。機密データを扱う場合は、オンプレミス導入を推奨します。
2. パイロットプロジェクトの実施
小規模なデータセットで概念実証を行い、期待する精度や性能が得られるかを確認してください。この段階で最適なEmbeddingモデルや検索手法を特定できます。
3. プロンプトエンジニアリングの最適化
システムプロンプトやFew-shot例示を活用して、回答品質の向上を図ってください。特に、業界特有の用語や表現スタイルに対応するための調整が重要です。
4. Re-rankモデルの活用
検索精度をさらに向上させるため、Re-rankモデルの導入を検討してください。複雑な質問や専門的な内容に対する回答精度が大幅に改善されます。
継続的な改善のポイント
RAGシステムは構築後の継続的な改善が成功の鍵となります:
- 定期的なデータ更新:情報の鮮度を保つための運用プロセスの確立
- ユーザーフィードバックの収集:実際の利用状況に基づく改善点の特定
- 最新技術の導入:Difyの新機能や最新のEmbeddingモデルの積極的な活用
DifyによるRAG構築は、企業のAI導入における重要な選択肢となります。適切な計画と継続的な改善により、業務効率の大幅な向上と新しい価値創造を実現できるでしょう。